MySQLĮyėŗą┼ŽóĄ─įö╝ÜĖ┼╩÷
░l▒ĒĢrķgŻ║2023-07-14 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP▄ø╝■ŽÓĻP╬─š┬╚╦ÜŌŻ║
[š¬ę¬]▒ŠŲ¬╬─š┬═©▀^Įyėŗą┼ŽóĄ─Ė┼─ŅĮķĮBęį╝░MYSQLĮyėŗą┼ŽóĄ─ā×ä▌Ą╚ĘĮ├µ╚½├µĖ┼╩÷┴╦MySQLĮyėŗą┼ŽóĄ─ŽÓĻPų¬ūR³cŻ¼ŽŻ═¹┐╔ęįÄ═ų·ĄĮėąąĶŪ¾Ą─┼¾ėčéāĪŻMySQLł╠ąąSQLĢ■Įø▀^SQLĮŌ╬÷║═▓ķįāā×╗»Ą─▀^│╠Ż¼ĮŌ╬÷Ų„īó...
▒ŠŲ¬╬─š┬═©▀^Įyėŗą┼ŽóĄ─Ė┼─ŅĮķĮBęį╝░MYSQLĮyėŗą┼ŽóĄ─ā×ä▌Ą╚ĘĮ├µ╚½├µĖ┼╩÷┴╦MySQLĮyėŗą┼ŽóĄ─ŽÓĻPų¬ūR³cŻ¼ŽŻ═¹┐╔ęįÄ═ų·ĄĮėąąĶŪ¾Ą─┼¾ėčéāĪŻ
MySQLł╠ąąSQLĢ■Įø▀^SQLĮŌ╬÷║═▓ķįāā×╗»Ą─▀^│╠Ż¼ĮŌ╬÷Ų„īóSQLĘųĮŌ│╔öĄō■ĮYśŗ▓óé„▀fĄĮ║¾└m▓Į¾EŻ¼▓ķįāā×╗»Ų„░l¼Fł╠ąąSQL▓ķįāĄ─ūŅ╝čĘĮ░ĖĪó╔·│╔ł╠ąąėŗäØĪŻ▓ķįāā×╗»Ų„øQČ©SQL╚ń║╬ł╠ąąŻ¼ę└┘ćė┌öĄō■ÄņĄ─Įyėŗą┼ŽóŻ¼Ž┬├µ╬ęéāĮķĮBMySQL 5.7ųąinnodbĮyėŗą┼ŽóĄ─ŽÓĻPā╚╚▌ĪŻ
MySQLĮyėŗą┼ŽóĄ─┤µā”Ęų×ķā╔ĘNŻ¼ĘŪ│ųŠ├╗»║═│ųŠ├╗»Įyėŗą┼ŽóĪŻ
ę╗ĪóĘŪ│ųŠ├╗»Įyėŗą┼Žó
ĘŪ│ųŠ├╗»Įyėŗą┼Žó┤µā”į┌ā╚┤µ└’Ż¼╚ń╣¹öĄō■ÄņųžåóŻ¼Įyėŗą┼ŽóīóüG╩¦ĪŻėąā╔ĘNĘĮ╩Į┐╔ęįįOų├×ķĘŪ│ųŠ├╗»Įyėŗą┼ŽóŻ║
1 ╚½Šųūā┴┐Ż¼ INNODB_STATS_PERSISTENT=OFF |
2 CREATE/ALTER▒ĒĄ─ģóöĄŻ¼ STATS_PERSISTENT=0 |
ĘŪ│ųŠ├╗»Įyėŗą┼Žóį┌ęįŽ┬ŪķørĢ■▒╗ūįäėĖ³ą┬Ż║
1 ł╠ąąANALYZE TABLE |
2 innodb_stats_on_metadata=ONŪķørŽ┬Ż¼ł╠SHOW TABLE STATUS, SHOW INDEX, ▓ķįā INFORMATION_SCHEMAŽ┬Ą─TABLES, STATISTICS |
3 åóė├--auto-rehash╣”─▄ŪķørŽ┬Ż¼╩╣ė├mysql clientĄŪõø |
4 ▒ĒĄ┌ę╗┤╬▒╗┤“ķ_ |
5 ŠÓ╔Žę╗┤╬Ė³ą┬Įyėŗą┼ŽóŻ¼▒Ē1/16Ą─öĄō■▒╗ą▐Ė─ |
ĘŪ│ųŠ├╗»Įyėŗą┼ŽóĄ─╚▒³c’@Č°ęūęŖŻ¼öĄō■Äņųžåó║¾╚ń╣¹┤¾┴┐▒Ēķ_╩╝Ė³ą┬Įyėŗą┼ŽóŻ¼Ģ■ī”īŹ└²įņ│╔║▄┤¾ė░ĒæŻ¼╦∙ęį─┐Ū░Č╝Ģ■╩╣ė├│ųŠ├╗»Įyėŗą┼ŽóĪŻ
Č■Īó│ųŠ├╗»Įyėŗą┼Žó
5.6.6ķ_╩╝Ż¼MySQL─¼šJ╩╣ė├┴╦│ųŠ├╗»Įyėŗą┼ŽóŻ¼╝┤INNODB_STATS_PERSISTENT=ONŻ¼│ųŠ├╗»Įyėŗą┼Žó▒Ż┤µį┌▒Ēmysql.innodb_table_stats║═mysql.innodb_index_statsĪŻ
│ųŠ├╗»Įyėŗą┼Žóį┌ęįŽ┬ŪķørĢ■▒╗ūįäėĖ³ą┬Ż║
1 INNODB_STATS_AUTO_RECALC=ON ŪķørŽ┬Ż¼▒Ēųą10%Ą─öĄō■▒╗ą▐Ė─ |
| 2 į÷╝ėą┬Ą─╦„ę² |
innodb_table_stats╩Ū▒ĒĄ─Įyėŗą┼ŽóŻ¼innodb_index_stats╩Ū╦„ę²Ą─Įyėŗą┼ŽóŻ¼Ė„ūųČ╬║¼┴x╚ńŽ┬Ż║
innodb_table_stats |
database_name | öĄō■Äņ├¹ |
table_name | ▒Ē├¹ |
last_update | Įyėŗą┼ŽóūŅ║¾ę╗┤╬Ė³ą┬Ģrķg |
n_rows | ▒ĒĄ─ąąöĄ |
clustered_index_size | Š█╝»╦„ę²Ą─ĒōĄ─öĄ┴┐ |
sum_of_other_index_sizes | Ųõ╦¹╦„ę²Ą─ĒōĄ─öĄ┴┐ |
innodb_index_stats |
database_name | öĄō■Äņ├¹ |
table_name | ▒Ē├¹ |
index_name | ╦„ę²├¹ |
last_update | Įyėŗą┼ŽóūŅ║¾ę╗┤╬Ė³ą┬Ģrķg |
stat_name | Įyėŗą┼Žó├¹ |
stat_value | Įyėŗą┼ŽóĄ─ųĄ |
sample_size | ▓╔śė┤¾ąĪ |
stat_description | ŅÉą═šf├„ |
×ķĖ³║├Ą─└ĒĮŌinnodb_index_statsŻ¼Į©ę╗Åł£yįć▒Ēū÷šf├„Ż║
CREATE TABLE t1 (
a INT, b INT, c INT, d INT, e INT, f INT,
PRIMARY KEY (a, b), KEY i1 (c, d), UNIQUE KEY i2uniq (e, f)
) ENGINE=INNODB;
īæ╚ļöĄō■╚ńŽ┬Ż║
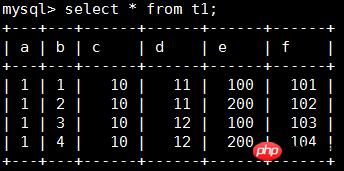
▓ķ┐┤t1▒ĒĄ─Įyėŗą┼ŽóŻ¼ąĶų„ę¬ĻPūóstat_name║═stat_valueūųČ╬
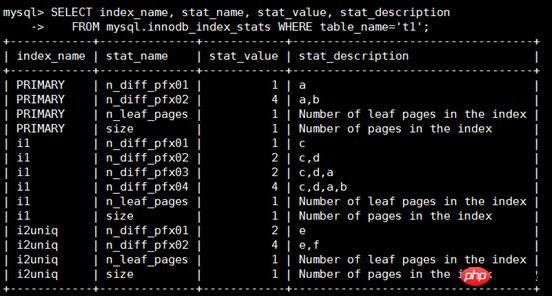
tat_name=sizeĢrŻ║stat_value▒Ē╩Š╦„ę²Ą─ĒōĄ─öĄ┴┐
stat_name=n_leaf_pagesĢrŻ║stat_value▒Ē╩Š╚~ūė╣سcĄ─öĄ┴┐
stat_name=n_diff_pfxNNĢrŻ║stat_value▒Ē╩Š╦„ę²ūųČ╬╔Ž╬©ę╗ųĄĄ─öĄ┴┐Ż¼┤╦╠Äū÷ę╗Ž┬Š▀¾wšf├„Ż║
1Īón_diff_pfx01▒Ē╩Š╦„ę²Ą┌ę╗┴ądistinctų«║¾Ą─öĄ┴┐Ż¼╚ńPRIMARYĄ─a┴ąŻ¼ų╗ėąę╗éĆųĄ1Ż¼╦∙ęįindex_name='PRIMARY' and stat_name='n_diff_pfx01'ĢrŻ¼stat_value=1ĪŻ
2Īón_diff_pfx02▒Ē╩Š╦„ę²Ū░ā╔┴ądistinctų«║¾Ą─öĄ┴┐Ż¼╚ńi2uniqĄ─e,f┴ąŻ¼ėą4éĆųĄŻ¼╦∙ęįindex_name='i2uniq' and stat_name='n_diff_pfx02'ĢrŻ¼stat_value=4ĪŻ
3Īóī”ė┌ĘŪ╬©ę╗╦„ę²Ż¼Ģ■į┌įŁėą┴ąų«║¾╝ė╔Žų„µI╦„ę²Ż¼╚ńindex_name='i1' and stat_name='n_diff_pfx03'Ż¼į┌įŁ╦„ę²┴ąc,d║¾╝ė┴╦ų„µI┴ąaŻ¼(c,d,a)Ą─distinctĮY╣¹×ķ2ĪŻ
┴╦ĮŌ┴╦stat_name║═stat_valueĄ─Š▀¾w║¼┴xŻ¼Š═┐╔ęįģfų·╬ęéā┼┼▓ķSQLł╠ąąĢr×ķ╩▓├┤ø]ėą╩╣ė├║Ž▀mĄ─╦„ę²Ż¼└²╚ń─│éĆ╦„ę²n_diff_pfxNNĄ─stat_value▀hąĪė┌īŹļHųĄŻ¼▓ķįāā×╗»Ų„šJ×ķįō╦„ę²▀xō±Č╚▌^▓ŅŻ¼Š═ėą┐╔─▄ī¦ų┬╩╣ė├Õeš`Ą─╦„ę²ĪŻ
╚²ĪóĮyėŗą┼Žó▓╗£╩┤_Ą─╠Ä└Ē
╬ęéā▓ķ┐┤ł╠ąąėŗäØŻ¼░l¼F╬┤╩╣ė├š²┤_Ą─╦„ę²Ż¼╚ń╣¹╩Ūinnodb_index_statsųąĮyėŗą┼Žó▓Ņäe▌^┤¾ę²ŲŻ¼┐╔═©▀^ęįŽ┬ĘĮ╩Į╠Ä└ĒŻ║
1Īó╩ųäėĖ³ą┬Įyėŗą┼ŽóŻ¼ūóęŌł╠ąą▀^│╠ųąĢ■╝ėūxµiŻ║
ANALYZETABLE TABLE_NAME;
2Īó╚ń╣¹Ė³ą┬║¾Įyėŗą┼Žó╚į▓╗£╩┤_Ż¼┐╔┐╝æ]į÷╝ė▒Ē▓╔śėĄ─öĄō■ĒōŻ¼ā╔ĘNĘĮ╩Į┐╔ęįą▐Ė─Ż║
a) ╚½Šųūā┴┐INNODB_STATS_PERSISTENT_SAMPLE_PAGESŻ¼─¼šJ×ķ20Ż╗
b) å╬éĆ▒Ē┐╔ęįųĖČ©įō▒ĒĄ─▓╔śėŻ║
ALTER TABLE TABLE_NAME STATS_SAMPLE_PAGES=40;
Įø£yįćŻ¼┤╦╠ÄSTATS_SAMPLE_PAGESĄ─ūŅ┤¾ųĄ╩Ū65535Ż¼│¼│÷Ģ■ł¾ÕeĪŻ
─┐Ū░MySQL▓óø]ėą╠ß╣®ų▒ĘĮłDĄ─╣”─▄Ż¼─│ą®ŪķørŽ┬Ż©╚ńöĄō■Ęų▓╝▓╗Š∙Ż®āHāHĖ³ą┬Įyėŗą┼Žó▓╗ę╗Č©─▄Ą├ĄĮ£╩┤_Ą─ł╠ąąėŗäØŻ¼ų╗─▄═©▀^index hintĄ─ĘĮ╩ĮųĖČ©╦„ę²ĪŻą┬░µ▒Š8.0Ģ■į÷╝ėų▒ĘĮłD╣”─▄Ż¼ūī╬ęéāŲ┌┤²MySQLįĮüĒįĮÅŖ┤¾Ą─╣”─▄░╔ŻĪ
ŽÓĻP═Ų╦]Ż║
īŹ└²ĮŌ╬÷Ż║Įyėŗą┼Žó╣▄└ĒĪóSpringūóĮŌķ_░l║═EasyUI
╩š╝»SQL ServerĮyėŗą┼Žó_PHPĮ╠│╠
ęį╔ŽŠ═╩ŪMySQLĮyėŗą┼ŽóĄ─įö╝ÜĖ┼╩÷Ą─įö╝Üā╚╚▌Ż¼Ė³ČÓšłĻPūóphpųą╬─ŠWŲõ╦³ŽÓĻP╬─š┬ŻĪ
īW┴ĢĮ╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
