├└łFŠWšŠĄ─öĄō■╦č╦„┼┼ą“╠Ä└ĒĘĮ░ĖŠ½╚AĘųŽĒ
░l▒ĒĢrķgŻ║2023-06-01 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP▄ø╝■ŽÓĻP╬─š┬╚╦ÜŌŻ║
[š¬ę¬]├└łFŠWšŠĄ─öĄō■╦č╦„┼┼ą“ĮŌøQĘĮ░ĖŠ½╚AĘųŽĒ ę╗ĪóŠĆ╔ŽŲ¬ļSų°śI䚥─░lš╣Ż¼├└łFĄ─╔╠╝ę║═łF┘ÅöĄš²į┌’w╦┘į÷ķLĪŻ▀@ę╗▒│Š░Ž┬Ż¼╦č╦„┼┼ą“Ą─ųžę¬ąį’@Ą├Ė³╝ė═╗│÷Ż║┼┼ą“Ą─ā×╗»─▄Ä═ų·ė├æ¶Ė³▒ŃĮ▌ĄžšęĄĮØMūŃŲõąĶŪ¾...
ĪĪĪĪ├└łFŠWšŠĄ─öĄō■╦č╦„┼┼ą“ĮŌøQĘĮ░ĖŠ½╚AĘųŽĒ
ę╗ĪóŠĆ╔ŽŲ¬
ĪĪĪĪļSų°śI䚥─░lš╣Ż¼├└łFĄ─╔╠╝ę║═łF┘ÅöĄš²į┌’w╦┘į÷ķLĪŻ▀@ę╗▒│Š░Ž┬Ż¼╦č╦„┼┼ą“Ą─ųžę¬ąį’@Ą├Ė³╝ė═╗│÷Ż║┼┼ą“Ą─ā×╗»─▄Ä═ų·ė├æ¶Ė³▒ŃĮ▌ĄžšęĄĮØMūŃŲõąĶŪ¾Ą─╔╠╝ę║═łF┘ÅŻ¼Ė─▀Mė├涾w“ׯ¼╠ß╔²▐D╗»ą¦╣¹ĪŻ
ĪĪĪĪ║═é„ĮyŠWĒō╦č╦„å¢Ņ}ŽÓ▒╚Ż¼├└łFĄ─╦č╦„┼┼ą“ėąūį╔ĒĄ─╠ž³c——90%Ą─Į╗ęū░l╔·į┌ęŲäėČ╦ĪŻę╗ĘĮ├µŻ¼▀@ī”┼┼ą“Ą─éĆąį╗»╠ß│÷┴╦Ė³Ė▀Ą─ę¬Ū¾Ż¼└²╚ńį┌“╗Õü”▓ķįāŽ┬Ż¼▒▒Š®╬ÕĄ└┐┌Ą─╗ÕüĄĻAŻ¼ī”į┌╬ÕĄ└┐┌Ą─ė├æ¶U1üĒšf╩Ū║├Ą─ĮY╣¹Ż¼ī”į┌═¹Š®Ą─ė├æ¶U2üĒųv▓╗ę╗Č©╩Ū║├Ą─ĮY╣¹;┴Ēę╗ĘĮ├µŻ¼╬ęéāė╔┤╦Ęe└█┴╦ė├æ¶į┌┐═æ¶Č╦╔ŽžSĖ╗£╩┤_Ą─ąą×ķŻ¼ĮøĘų╬÷½@Ą├ė├æ¶Ą─Ąž└Ē╬╗ų├ĪóŲĘŅÉ║═ārĖ±Ą╚Ų½║├Ż¼▀MČ°ųĖī¦éĆąį╗»┼┼ą“ĪŻ
ĪĪĪĪßśī”├└łFĄ─O2OśIäš╠ž³cŻ¼╬ęéāīŹ¼F┴╦ę╗╠ū╦č╦„┼┼ą“╝╝ągĘĮ░ĖŻ¼ŽÓ▒╚ęÄät┼┼ą“ėą░┘Ęųų«Äū╩«Ą─╠ß╔²ĪŻ╗∙ė┌▀@ę╗ĘĮ░ĖŻ¼╬ęéāėų│ķŽ¾┴╦ę╗╠ū═©ė├Ą─O2O┼┼ą“ĮŌøQĘĮ░ĖŻ¼ų╗ąĶ1-2╠ņŠ═┐╔ęį┐ņ╦┘Ąž▓┐╩ĄĮŲõ╦¹«aŲĘ║═ūėąąśIųąŻ¼─┐Ū░į┌¤ßį~ĪóSuggestionĪóŠŲĄĻĪóKTVĄ╚ČÓéĆ«aŲĘ║═ūėąąśIųąæ¬ė├ĪŻ
ĪĪĪĪ╬ęéāīó░┤ŠĆ╔Ž║═ŠĆŽ┬ā╔▓┐ĘųĘųäeĮķĮB▀@ę╗═©ė├O2O┼┼ą“ĮŌøQĘĮ░ĖŻ¼▒Š╬─╩ŪŠĆ╔ŽŲ¬Ż¼ų„ę¬ĮķĮBį┌ŠĆĘ■äš┐“╝▄Īó╠žš„╝ė▌dĪóį┌ŠĆŅA╣└Ą╚─ŻēKŻ¼Ž┬Ų¬īóĢ■ų°ųžĮķĮBļxŠĆ┴„│╠ĪŻ
ĪĪĪĪ┼┼ą“ŽĄĮy
ĪĪĪĪ×ķ┴╦┐ņ╦┘ėąą¦Ą─▀Mąą╦č╦„╦ŃĘ©Ą─Ą³┤·Ż¼┼┼ą“ŽĄĮyįOėŗ╔Žų¦│ųņ`╗ŅĄ─A/B£yįćŻ¼ØMūŃ£╩┤_ą¦╣¹ūĘ█ÖĄ─ąĶŪ¾ĪŻ
ĪĪĪĪ├└łF╦č╦„┼┼ą“ŽĄĮy╚ń╔ŽłD╦∙╩ŠŻ¼ų„ę¬░³└©ļxŠĆöĄō■╠Ä└ĒĪóŠĆ╔ŽĘ■äš║═į┌ŠĆöĄō■╠Ä└Ē╚²éĆ─ŻēKĪŻ
ĪĪĪĪļxŠĆöĄō■╠Ä└Ē
ĪĪĪĪHDFS/Hive╔Ž┤µā”┴╦╦č╦„š╣╩ŠĪó³cō¶ĪóŽ┬å╬║═ų¦ĖČĄ╚╚šųŠĪŻļxŠĆöĄō■┴„│╠░┤╠ņš{Č╚ČÓéĆMap Reduce╚╬äšĘų╬÷╚šųŠŻ¼ŽÓĻP╚╬äš░³└©Ż║
ĪĪĪĪļxŠĆ╠žš„═┌Š“
ĪĪĪĪ«a│÷Deal(łF┘Åå╬)/POI(╔╠╝ę)Īóė├æ¶║═QueryĄ╚ŠSČ╚Ą─╠žš„╣®┼┼ą“─Żą═╩╣ė├ĪŻ
ĪĪĪĪöĄō■ŪÕŽ┤ś╦ūó & ─Żą═ė¢ŠÜ
ĪĪĪĪöĄō■ŪÕŽ┤╚źĄ¶┼└ŽxĪóū„▒ūĄ╚ę²╚ļĄ─┼KöĄō■;ŪÕŽ┤═ĻĄ─öĄō■Įø▀^ś╦ūó║¾ė├ū„─Żą═ė¢ŠÜĪŻ
ĪĪĪĪą¦╣¹ł¾▒Ē╔·│╔
ĪĪĪĪĮyėŗ╔·│╔╦ŃĘ©ą¦╣¹ųĖś╦Ż¼ųĖī¦┼┼ą“Ė─▀MĪŻ
ĪĪĪĪ╠žš„▒O┐ž
ĪĪĪĪ╠žš„ū„×ķ┼┼ą“─Żą═Ą─▌ö╚ļ╩Ū┼┼ą“ŽĄĮyĄ─╗∙ĄAĪŻ╠žš„Ą─Õeš`«É│ŻūāäėĢ■ų▒Įėė░Ēæ┼┼ą“Ą─ą¦╣¹ĪŻ╠žš„▒O┐žų„ę¬▒O┐ž╠žš„Ė▓╔w┬╩║═╚ĪųĄĘų▓╝Ż¼Ä═╬ęéā╝░Ģr░l¼FŽÓĻPå¢Ņ}ĪŻ
ĪĪĪĪį┌ŠĆöĄō■╠Ä└Ē
ĪĪĪĪ║═ļxŠĆ┴„│╠ŽÓī”æ¬Ż¼į┌ŠĆ┴„│╠═©▀^Storm/Spark StreamingĄ╚╣żŠ▀ī”īŹĢr╚šųŠ┴„▀MąąĘų╬÷╠Ä└ĒŻ¼«a│÷īŹĢr╠žš„ĪóīŹĢrł¾▒Ē║═▒O┐žöĄō■Ż¼Ė³ą┬į┌ŠĆ┼┼ą“─Żą═ĪŻ
ĪĪĪĪį┌ŠĆĘ■äš(Rank Service)
ĪĪĪĪRank ServiceĮėĄĮ╦č╦„šłŪ¾║¾Ż¼Ģ■š{ė├š┘╗žĘ■äš½@╚Ī║“▀xPOI/Deal╝»║ŽŻ¼Ė∙ō■A/B£yįć┼õų├×ķė├æ¶Ęų┼õ┼┼ą“▓▀┬į/─Żą═Ż¼æ¬ė├▓▀┬į/─Żą═ī”║“▀x╝»║Ž▀Mąą┼┼ą“ĪŻ
ĪĪĪĪŽ┬łD╩ŪRank Serviceā╚▓┐Ą─┼┼ą“┴„│╠ĪŻ
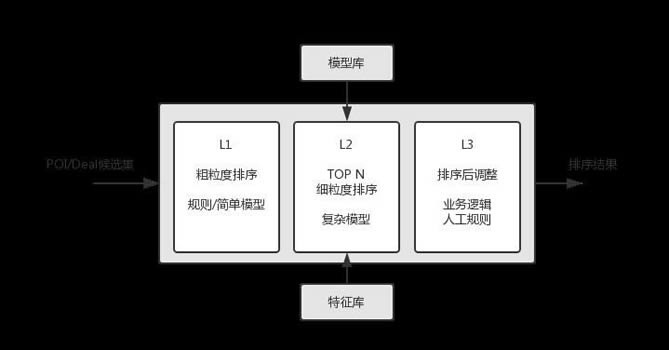
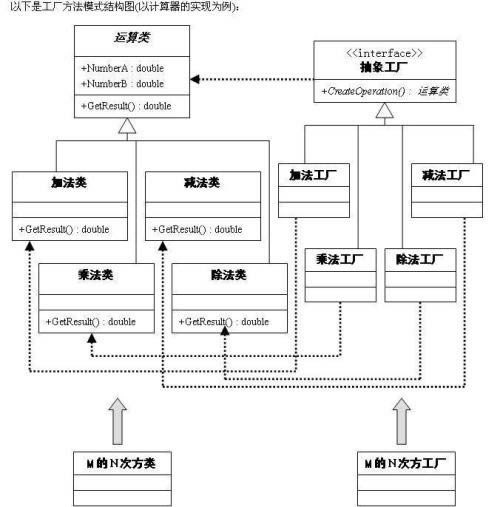
ĪĪĪĪL1 ┤ų┴ŻČ╚┼┼ą“(┐ņ╦┘)
ĪĪĪĪ╩╣ė├▌^╔┘Ą─╠žš„Īó║åå╬Ą──Żą═╗“ęÄätī”║“▀x╝»▀Mąą┤ų┴ŻČ╚┼┼ą“ĪŻ
ĪĪĪĪL2 ╝Ü┴ŻČ╚┼┼ą“(▌^┬²)
ĪĪĪĪī”L1┼┼ą“ĮY╣¹Ą─Ū░NéĆ▀Mąą╝Ü┴ŻČ╚┼┼ą“ĪŻ▀@ę╗īėĢ■Å─╠žš„Äņ╝ė▌d╠žš„(═©▀^FeatureLoader)Ż¼æ¬ė├─Żą═(A/B£yįć┼õų├Ęų┼õ)▀Mąą┼┼ą“ĪŻ
ĪĪĪĪL3 śIäšęÄätĖ╔ŅA
ĪĪĪĪį┌L2┼┼ą“Ą─╗∙ĄA╔ŽŻ¼æ¬ė├śIäšęÄät/╚╦╣żĖ╔ŅAī”┼┼ą“▀Mąą▀m«öš{š¹ĪŻ
ĪĪĪĪRank ServiceĢ■īóš╣╩Š╚šųŠėøõøĄĮ╚šųŠ╩š╝»ŽĄĮyŻ¼╣®į┌ŠĆ/ļxŠĆ╠Ä└ĒĪŻ
ĪĪĪĪA/B£yįć
ĪĪĪĪA/B£yįćĄ─┴„┴┐ŪąĘų╩Ūį┌Rank ServerČ╦═Ļ│╔Ą─ĪŻ╬ęéāĖ∙ō■UUID(ė├æ¶ś╦ūR)īó┴„┴┐ŪąĘų×ķČÓéĆ═░(Bucket)Ż¼├┐éĆ═░ī”æ¬ę╗ĘN┼┼ą“▓▀┬įŻ¼═░ā╚┴„┴┐īó╩╣ė├ŽÓæ¬Ą─▓▀┬į▀Mąą┼┼ą“ĪŻ╩╣ė├UUID▀Mąą┴„┴┐ŪąĘųŻ¼╩Ū×ķ┴╦▒ŻūCė├涾w“ץ─ę╗ų┬ąįĪŻ
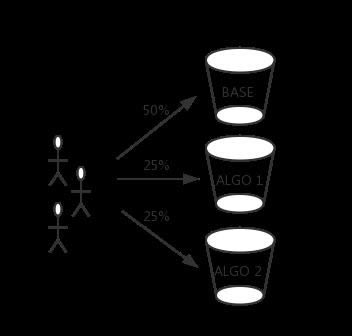
ĪĪĪĪŽ┬├µ╩ŪA/B£yįć┼õų├Ą─ę╗éĆ║åå╬╩Š└²ĪŻ
ĪĪĪĪ┤·┤a╚ńŽ┬:
ĪĪĪĪ{
ĪĪĪĪ"search": {
ĪĪĪĪ"NumberOfBuckets": 100,
ĪĪĪĪ"DefaultStrategy": "Base",
ĪĪĪĪ"Segments": [
ĪĪĪĪ{
ĪĪĪĪ"BeginBucket": 0,
ĪĪĪĪ"EndBucket": 24,
ĪĪĪĪ"WhiteList": [123],
ĪĪĪĪ"Strategy": "Algo-1"
ĪĪĪĪ},
ĪĪĪĪ{
ĪĪĪĪ"BeginBucket": 25,
ĪĪĪĪ"EndBucket": 49,
ĪĪĪĪ"WhiteList": [],
ĪĪĪĪ"Strategy": "Algo-2"
ĪĪĪĪ}
ĪĪĪĪ]
ĪĪĪĪ}
ĪĪĪĪ}
ĪĪĪĪī”ė┌▓╗║ŽĘ©Ą─UUIDŻ¼├┐┤╬šłŪ¾Ģ■ļSÖCĘų┼õę╗éĆ═░Ż¼ęį▒ŻūCą¦╣¹ī”▒╚▓╗╩▄ė░ĒæĪŻ░ū├¹å╬(White List)ÖCųŲ─▄▒ŻūC┼õų├ė├æ¶╩╣ė├ĮoČ©Ą─▓▀┬įŻ¼ęį▌oų·ŽÓĻPĄ─£yįćĪŻ
ĪĪĪĪ│²┴╦A/B£yįćų«═ŌŻ¼╬ęéā▀Ćæ¬ė├┴╦Interleaving[7]ĘĮĘ©Ż¼ė├ė┌▒╚▌^ā╔ĘN┼┼ą“╦ŃĘ©ĪŻŽÓ▌^ė┌A/B£yįćŻ¼InterleavingĘĮĘ©ī”┼┼ą“╦ŃĘ©Ė³ņ`├¶Ż¼─▄═©▀^Ė³╔┘Ą─śė▒ŠüĒ▒╚▌^ā╔ĘN┼┼ą“╦ŃĘ©ų«ķgĄ─ā×┴ėĪŻInterleavingĘĮĘ©╩╣ė├▌^ąĪ┴„┴┐Ä═ų·╬ęéā┐ņ╦┘╠į╠Ł▌^▓Ņ╦ŃĘ©Ż¼╠ßĖ▀▓▀┬įĄ³┤·ą¦┬╩ĪŻ
ĪĪĪĪ╠žš„╝ė▌d
ĪĪĪĪ╦č╦„┼┼ą“Ę■äš╔µ╝░ČÓĘNŅÉą═Ą─╠žš„Ż¼╠žš„½@╚Ī║═ėŗ╦Ń╩ŪRank ServiceĒææ¬╦┘Č╚Ą─Ų┐ŅiĪŻ╬ęéāįOėŗ┴╦FeatureLoader─ŻēKŻ¼Ė∙ō■╠žš„ę└┘ćĻPŽĄŻ¼▓󹹥ž½@╚Ī║═ėŗ╦Ń╠žš„Ż¼ėąą¦Ąž£p╔┘┴╦╠žš„╝ė▌dĢrķgĪŻīŹļHśIäšųąŻ¼▓óąą╠žš„╝ė▌dŲĮŠ∙Ēææ¬Ģrķg▒╚┤«ąą╠žš„╝ė▌d┐ņ╝s20║┴├ļĪŻ
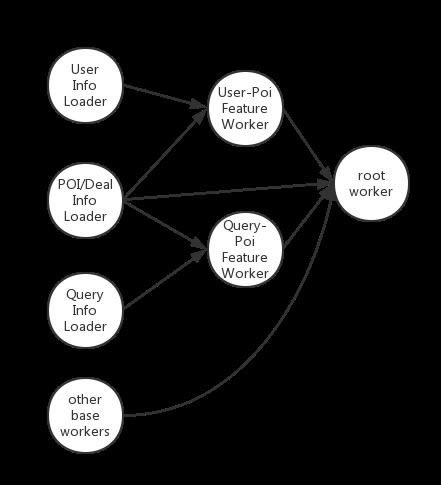
ĪĪĪĪFeatureLoaderĄ─īŹ¼Fųą╬ęéā╩╣ė├┴╦Akka[8]ĪŻ╚ń╔ŽłD╦∙╩ŠŻ¼╠žš„½@╚Ī║═ėŗ╦ŃĄ─▒╗│ķŽ¾║═ĘŌčb×ķ┴╦╚¶Ė╔éĆAkka actorŻ¼ė╔Akkaš{Č╚Īó▓óąął╠ąąĪŻ
ĪĪĪĪ╠žš„║═─Żą═
ĪĪĪĪ├└łFÅ─2013─Ļ9į┬ķ_╩╝į┌╦č╦„┼┼ą“╔Žæ¬ė├ÖCŲ„īW┴ĢĘĮĘ©(Learning to Rank)Ż¼▓óŪę╚ĪĄ├║▄┤¾Ą─╩šęµĪŻ▀@Ą├ęµė┌£╩┤_Ą─öĄō■ś╦ūóŻ║ė├æ¶Ą─³cō¶Ž┬å╬ų¦ĖČĄ╚ąą×ķ─▄ėąą¦ĄžĘ┤ė│ŲõŲ½║├ĪŻ═©▀^į┌╠žš„═┌Š“║═─Żą═ā×╗»ā╔ĘĮ├µĄ─╣żū„Ż¼╬ęéā▓╗öÓĄžā×╗»╦č╦„┼┼ą“ĪŻŽ┬├µīóĮķĮB╬ęéāį┌╠žš„╩╣ė├ĪóöĄō■ś╦ūóĪó┼┼ą“╦ŃĘ©ĪóPosition Bias╠Ä└Ē║═└õåóäėå¢Ņ}ŠÅĮŌĄ╚ĘĮ├µĄ─╣żū„ĪŻ
ĪĪĪĪ╠žš„
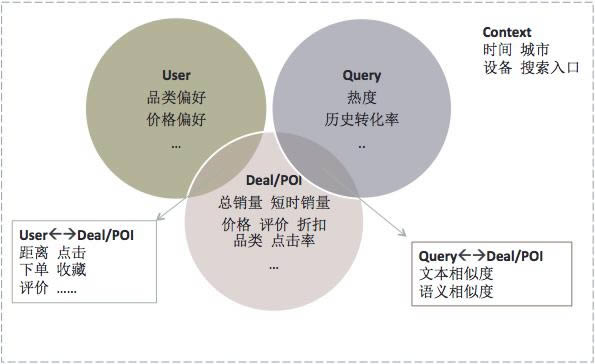
ĪĪĪĪÅ─├└łFśIäš│÷░lŻ¼╠žš„▀x╚Īų°č█ė┌ė├æ¶ĪóQueryĪóDeal/POI║═╦č╦„╔ŽŽ┬╬─╦─éĆŠSČ╚ĪŻ
ĪĪĪĪė├涊SČ╚
ĪĪĪĪ░³└©═┌Š“Ą├ĄĮĄ─ŲĘŅÉŲ½║├ĪóŽ¹┘M╦«ŲĮ║═Ąž└Ē╬╗ų├Ą╚ĪŻ
ĪĪĪĪQueryŠSČ╚
ĪĪĪĪ░³└©QueryķLČ╚ĪóÜv╩Ę³cō¶┬╩Īó▐D╗»┬╩║═ŅÉą═(╔╠╝ęį~/ŲĘŅÉį~/Ąžś╦į~)Ą╚ĪŻ
ĪĪĪĪDeal/POIŠSČ╚
ĪĪĪĪ░³└©Deal/POIõN┴┐ĪóārĖ±ĪóįuārĪóš█┐█┬╩ĪóŲĘŅÉ║═Üv╩Ę▐D╗»┬╩Ą╚ĪŻ
ĪĪĪĪ╔ŽŽ┬╬─ŠSČ╚
ĪĪĪĪ░³└©ĢrķgĪó╦č╦„╚ļ┐┌Ą╚ĪŻ
ĪĪĪĪ┤╦═ŌŻ¼ėąĄ─╠žš„üĒūįė┌ÄūéĆŠSČ╚ų«ķgĄ─ŽÓ╗źĻPŽĄŻ║ė├æ¶ī”Deal/POIĄ─³cō¶║═Ž┬å╬Ą╚ąą×ķĪóė├æ¶┼cPOIĄ─ŠÓļxĄ╚╩ŪøQČ©┼┼ą“Ą─ųžę¬ę“╦ž;Query║═Deal/POIĄ─╬─▒ŠŽÓĻPąį║═šZ┴xŽÓĻPąį╩Ū─Żą═Ą─ĻPµI╠žš„ĪŻ
ĪĪĪĪ─Żą═
ĪĪĪĪLearning to Rankæ¬ė├ųąŻ¼╬ęéāų„ę¬▓╔ė├┴╦PointwiseĘĮĘ©ĪŻ▓╔ė├ė├æ¶Ą─³cō¶ĪóŽ┬å╬║═ų¦ĖČĄ╚ąą×ķüĒ▀Mąąš²śė▒ŠĄ─ś╦ūóĪŻÅ─Įyėŗ╔Ž┐┤Ż¼³cō¶ĪóŽ┬å╬║═ų¦ĖČĄ╚ąą×ķĘųäeī”æ¬┴╦įōśė▒Šī”ė├æ¶ąĶŪ¾Ą─▓╗═¼Ą─Ųź┼õ│╠Č╚Ż¼ę“┤╦ī”æ¬Ą─śė▒ŠĢ■▒╗«öū÷š²śė▒ŠŻ¼Ūę┘xėĶ▓╗öÓį÷┤¾Ą─ÖÓųžĪŻ
ĪĪĪĪŠĆ╔Ž▀\ąąų°ČÓĘN▓╗═¼ŅÉą═─Żą═Ż¼ų„ę¬░³└©Ż║
ĪĪĪĪGradient boosting decision/regression tree(GBDT/GBRT)
ĪĪĪĪGBDT╩ŪLTRųąæ¬ė├▌^ČÓĄ─ĘŪŠĆąį─Żą═ĪŻ╬ęéāķ_░l┴╦╗∙ė┌SparkĄ─GBDT╣żŠ▀Ż¼śõöM║Ž╠▌Č╚Ą─Ģr║“▀\ė├┴╦▓óąąĘĮĘ©Ż¼┐sČ╠ė¢ŠÜĢrķgĪŻGBDTĄ─śõ▒╗įOėŗ×ķ╚²▓µśõŻ¼ū„×ķę╗ĘN╠Ä└Ē╠žš„╚▒╩¦Ą─ĘĮĘ©ĪŻ
ĪĪĪĪ▀xō±▓╗═¼Ą─ōp╩¦║»öĄŻ¼boosting treeĘĮĘ©┐╔ęį╠Ä└Ē╗žÜwå¢Ņ}║═ĘųŅÉå¢Ņ}ĪŻæ¬ė├ųąŻ¼╬ęéā▀xė├┴╦ą¦╣¹Ė³║├Ą─logistic likelihood lossŻ¼īóå¢Ņ}Į©─Ż×ķČ■ĘųŅÉå¢Ņ}ĪŻ
ĪĪĪĪLogistic Regression(LR)
ĪĪĪĪģó┐╝FacebookĄ─paper[3]Ż¼╬ęéā└¹ė├GBDT▀Mąą▓┐ĘųLR╠žš„Ą─śŗĮ©ĪŻė├FTRL╦ŃĘ©üĒį┌ŠĆė¢ŠÜLR─Żą═ĪŻ
ĪĪĪĪī”─Żą═Ą─įu╣└Ęų×ķļxŠĆ║═ŠĆ╔Žā╔▓┐ĘųĪŻļxŠĆ▓┐Ęų╬ęéā═©▀^AUC(Area Under the ROC Curve)║═MAP(Mean Average Precision)üĒįuār─Żą═Ż¼ŠĆ╔Žät═©▀^A/B£yįćüĒÖz“×─Żą═Ą─īŹļHą¦╣¹Ż¼ā╔ĒŚ╩ųČ╬ų¦ō╬ų°╦ŃĘ©▓╗öÓĄ─Ą³┤·ā×╗»ĪŻ
ĪĪĪĪ└õåóäė
ĪĪĪĪį┌╬ęéāĄ─╦č╦„┼┼ą“ŽĄĮyųąŻ¼└õåóäėå¢Ņ}▒Ē¼F×ķ«öą┬Ą─╔╠╝ęĪóą┬Ą─łF┘Åå╬õø╚ļ╗“ą┬Ą─ė├æ¶╩╣ė├├└łFĢrŻ¼╬ęéāø]ėąūŃē“Ą─öĄō■ė├üĒ═Ų£yė├æ¶ī”«aŲĘĄ─Ž▓║├ĪŻ╔╠╝ę└õåóäė╩Ūų„ę¬å¢Ņ}Ż¼╬ęéā═©▀^ā╔ĘĮ├µ╩ųČ╬üĒ▀MąąŠÅĮŌĪŻę╗ĘĮ├µŻ¼į┌─Żą═ųąę²╚ļ┴╦╬─▒ŠŽÓĻPąįĪóŲĘŅÉŽÓ╦ŲČ╚ĪóŠÓļx║═ŲĘŅÉī┘ąįĄ╚╠žš„Ż¼┤_▒Żį┌ø]ėąūŃē“š╣╩Š║═Ę┤üĄ─Ū░╠ߎ┬─▄▌^×ķ£╩┤_ĄžŅA£y;┴Ēę╗ĘĮ├µŻ¼╬ęéāę²╚ļ┴╦Explore&ExploitÖCųŲŻ¼ī”ą┬╔╠╝ę║═łFå╬ĮoėĶ▀mČ╚Ą─Ųž╣ŌÖCĢ■Ż¼ęį╩š╝»Ę┤üöĄō■▓óĖ─╔ŲŅA£yĪŻ
ĪĪĪĪPosition Bias
ĪĪĪĪį┌╩ųÖCČ╦Ż¼╦č╦„ĮY╣¹Ą─š╣¼Fą╬╩Į╩Ū┴ą▒ĒĒōŻ¼ĮY╣¹Ą─š╣╩Š╬╗ų├Ģ■ī”ė├æ¶ąą×ķ«a╔·║▄┤¾Ą─ė░ĒæĪŻį┌╠žš„═┌Š“║═ė¢ŠÜöĄō■ś╦ūó«öųąŻ¼╬ęéā┐╝æ]┴╦š╣╩Š╬╗ų├ę“╦žę²╚ļĄ─Ų½▓ŅĪŻ└²╚ńCTR(click-through-rate)Ą─ĮyėŗųąŻ¼╬ęéā╗∙ė┌Examination ModelŻ¼╚ź│²š╣╩Š╬╗ų├ĦüĒĄ─ė░ĒæĪŻ
ĪĪĪĪŠĆ╔ŽŲ¬┐éĮY
ĪĪĪĪŠĆ╔ŽŲ¬ų„ę¬ĮķĮB┴╦├└łF╦č╦„┼┼ą“ŽĄĮyŠĆ╔Ž▓┐ĘųĄ─ĮYśŗĪó╦ŃĘ©║═ų„ę¬─ŻēKĪŻį┌║¾└m╬─š┬└’Ż¼╬ęéāĢ■ų°ųžĮķĮB┼┼ą“ŽĄĮyļxŠĆ▓┐ĘųĄ─╣żū„ĪŻ
ĪĪĪĪę╗éĆ═Ļ╔ŲĄ─ŠĆ╔ŽŠĆŽ┬ŽĄĮy╩Ū┼┼ą“ā×╗»Ą├ęį│ų└m▀MąąĄ─╗∙ĄAĪŻ╗∙ė┌śIäšī”öĄō■║═─Żą═╔ŽĄ─▓╗öÓ═┌Š“╩Ū┼┼ą“│ų└mĖ─╔ŲĄ─äė┴”ĪŻ╬ęéā╚įį┌╠Į╦„ĪŻ
ĪĪĪĪČ■ĪóŠĆŽ┬Ų¬
ĪĪĪĪßśī”├└łF90%Ą─Į╗ęū░l╔·į┌ęŲäėČ╦Ą─śIäš╠ž³cŻ¼╬ęéāīŹ¼F┴╦ę╗╠ū▀mė├ė┌O2OśI䚥─╦č╦„┼┼ą“╝╝ągĘĮ░ĖŻ¼ęčį┌įSČÓ«aŲĘ║═ūėąąśIųąĄ├ĄĮæ¬ė├ĪŻį┌ų«Ū░Ą─ŠĆ╔ŽŲ¬ųąŻ¼╬ęéāęčĮøĮķĮB┴╦Ę■䚥─┐“╝▄Īó┼┼ą“╦ŃĘ©Ą╚ĪŻ▒Š╬─×ķŠĆŽ┬Ų¬Ż¼ų„ę¬ųv╩÷öĄō■ŪÕŽ┤Īó╠žš„ŠžĻćĪó▒O┐žŽĄĮyĪó─Żą═ė¢ŠÜ║═ą¦╣¹įu╣└Ą╚─ŻēKĪŻ
ĪĪĪĪöĄō■ŪÕŽ┤
ĪĪĪĪöĄō■ŪÕŽ┤Ą─ų„ę¬╣żū„╩Ū×ķļxŠĆ─Żą═ė¢ŠÜ£╩éõś╦ūóöĄō■Ż¼═¼ĢrŽ┤Ą¶▓╗║ŽĘ©öĄō■ĪŻöĄō■ŪÕŽ┤Ą─öĄō■į┤ų„ę¬ėąłF┘ÅĄ─Ųž╣ŌĪó³cō¶║═Ž┬å╬ĪŻ
ĪĪĪĪš¹éĆöĄō■ŪÕŽ┤Ą─┴„│╠╚ńŽ┬Ż║
ĪĪĪĪą“┴ą╗»
ĪĪĪĪŲž╣ŌĪó³cō¶║═Ž┬å╬öĄō■Å─Hive▒Ēųąūx╚ĪŻ¼▓╔ė├schemaĄ─╠Ä└ĒĘĮ╩ĮŻ¼┐╔ęįų▒ĮėĖ∙ō■╚šųŠūųČ╬├¹üĒ│ķ╚ĪŽÓæ¬Ą─ūųČ╬Ż¼▓╗╩▄╚šųŠūųČ╬į÷╝ė╗“š▀£p╔┘Ą─ė░ĒæĪŻ
ĪĪĪĪŲž╣Ō╚šųŠ┤µā”┴╦ę╗┤╬ė├æ¶ąą×ķĄ─įö╝Üą┼ŽóŻ¼░³└©│Ū╩ąĪóĄž└Ē╬╗ų├Īó║Y▀xŚl╝■╝░ę╗ą®ąą×ķ╠žš„;³cō¶╚šųŠų„ę¬ėøõø┴╦ė├涳cō¶Ą─POIIDĪó³cō¶Ģrķg;Ž┬å╬╚šųŠėøõø┴╦ė├涎┬å╬Ą─POIIDĪóŽ┬å╬Ģrķg║═Ž┬å╬Ą─ĮŅ~ĪŻöĄō■ŪÕŽ┤─ŻēKĖ∙ō■┼õų├╬─╝■Å─öĄō■į┤ųą│ķ╚ĪąĶꬥ─ūųČ╬Ż¼▀Mąąą“┴ą╗»(Serialization)ų«║¾┤µā”į┌HDFS╔ŽĪŻ
ĪĪĪĪą“┴ą╗»Ą─▀^│╠ųąŻ¼╚ń╣¹╚šųŠūųČ╬▓╗║ŽĘ©╗“š▀å╬ę╗ė├æ¶Ųž╣ŌĪó³cō¶╗“Ž┬å╬│¼│÷įOČ©Ą─ķōųĄŻ¼ŽÓĻP╚šųŠČ╝Ģ■▒╗ŪÕŽ┤Ą¶Ż¼▒▄├ŌöĄō■ī”─Żą═ė¢ŠÜįņ│╔ė░ĒæĪŻ
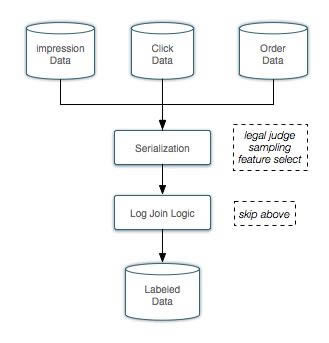
ĪĪĪĪöĄō■ś╦ūó
ĪĪĪĪöĄō■ą“┴ą╗»ų«║¾į┌HDFS╔Ž▒Ż┤µ╚²Ę▌╬─▒Š╬─╝■Ż¼Ęųäe╩ŪŲž╣Ō(Impression)Īó³cō¶(Click)║═Ž┬å╬(Order)ĪŻöĄō■ś╦ūó─ŻēKĖ∙ō■globalid(ę╗┤╬╦č╦„Ą─╚½Šų╬©ę╗ś╦╩ŠŻ¼ŅÉ╦Ųė┌sessionid)║═ŽÓæ¬Ą─łF┘Åid×ķkeyŻ¼īóŲž╣ŌĪó³cō¶║═Ž┬å╬ĻP┬ōŲüĒŻ¼ūŅĮK╔·│╔ę╗Ę▌ś╦ūó║├╩Ūʱ▒╗³cō¶ĪóŽ┬å╬Īóų¦ĖČĄ─ś╦ūóöĄō■ĪŻ═¼Ģr▀@Ę▌ś╦ūóöĄō■öyĦ┴╦▒Š┤╬š╣¼FĄ─įö╝Ü╠žš„ą┼ŽóĪŻ
ĪĪĪĪöĄō■ś╦ūó═©▀^ę╗┤╬Map/ReduceüĒ═Ļ│╔ĪŻ
ĪĪĪĪMapļAČ╬Ż║MapĄ─▌ö╚ļ×ķŲž╣ŌĪó³cō¶║═Ž┬å╬╚²ĘNHDFSöĄō■ĪŻ ė├╚²éĆMapperĘųäe╠Ä└Ē╚²ĘN╚šųŠĪŻöĄō■Ęų░lĄ─key×ķglobalidĪŻŲõųąŻ¼╚ń╣¹³cō¶║═Ž┬å╬öĄō■ųąĄ─globalidūųČ╬×ķ┐š("")Ż¼ätüGŚēįōŚl╚šųŠ(ę“×ķglobalid×ķ┐š¤oĘ©║═Ųž╣Ō╚šųŠjoinŻ¼Ģ■│÷¼Fš`ś╦ūó)ĪŻ
ĪĪĪĪReduceļAČ╬Ż║ReduceĮė╩šĄ─key×ķglobalid, values×ķŠ▀ėąŽÓ═¼globalidĄ─Ųž╣ŌĪó³cō¶ĪóŽ┬å╬öĄō■ListŻ¼▒ķÜvįōList, ╚ń╣¹
ĪĪĪĪ╚šųŠŅÉą═×ķŲž╣Ō╚šųŠŻ¼ätś╦ėøįōglobalidī”æ¬Ą─Ųž╣Ō╚šųŠ┤µį┌(imp_exist=true)ĪŻ
ĪĪĪĪ╚šųŠŅÉą═×ķ³cō¶╚šųŠŻ¼ätīóŲž╣Ō╚šųŠĄ─clickedūųČ╬ų├×ķ1ĪŻ
ĪĪĪĪ╚šųŠŅÉą═×ķŽ┬å╬╚šųŠŻ¼ätīóŲž╣Ō╚šųŠĄ─orderedūųČ╬ų├×ķ1ĪŻ
ĪĪĪĪ╚šųŠŅÉą═×ķŽ┬å╬╚šųŠŻ¼╚ń╣¹pay_accountūųČ╬>0Ż¼ ätīóŲž╣Ō╚šųŠĄ─paidūųČ╬ų├×ķ1ĪŻ
ĪĪĪĪ▒ķÜvListų«║¾Ż¼╚ń╣¹imp_exist == true, ätīóś╦ūó║├Ą─öĄō■īæ╚ļHDFSŻ¼ ʱätüGŚēĪŻ
ĪĪĪĪöĄō■ś╦ūóĄ─┴„│╠łD╚ńŽ┬Ż║
ĪĪĪĪ╠žš„ŠžĻć
ĪĪĪĪ╠žš„ŠžĻćĄ─ū„ė├╩Ū╠ß╣®žSĖ╗Ą─╠žš„╝»║ŽŻ¼ęįĘĮ▒Ńį┌ŠĆ║═ļxŠĆ╠žš„š{čą╩╣ė├ĪŻ
ĪĪĪĪ╠žš„ŠžĻćĄ─╔·│╔
ĪĪĪĪ╠žš„ŠžĻćĄ─╔·│╔┐“╝▄×ķŻ║
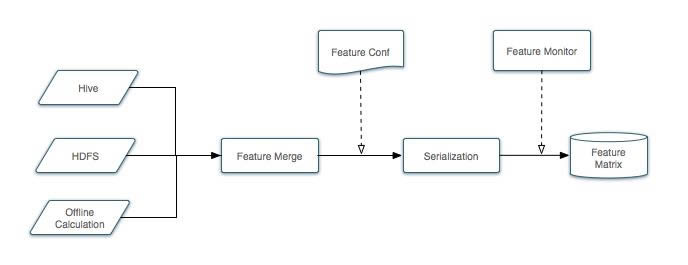
ĪĪĪĪŽ┬├µ╬ęéāüĒįö╝Üšf├„ę╗Ž┬┴„│╠ĪŻ
ĪĪĪĪ╗∙ĄA╠žš„░┤üĒį┤┐╔Ęų×ķ╚²▓┐ĘųŻ║
ĪĪĪĪ1ĪóHive▒ĒŻ║ėąę╗ą®╗∙ĄA╠žš„┤µā”į┌Hiveś╦ūóŻ¼╚ńPOIĄ─├¹ūųĪóŲĘŅÉĪółF┘ÅöĄĄ╚ĪŻ
ĪĪĪĪ2ĪóļxŠĆėŗ╦ŃŻ║ę╗ą®╠žš„ąĶę¬Ęe└█ę╗Č╬Ģrķg▓┼─▄ĮyėŗŻ¼╚ńPOIĄ─³cō¶┬╩ĪóõN┴┐Ą╚Ż¼▀@▓┐Ęų═©▀^Ęe└█Üv╩ĘöĄō■Ż¼╚╗║¾Įø▀^Map/Reduce╠Ä└ĒĄ├ĄĮĪŻ
ĪĪĪĪ3ĪóHDFSŻ║╠žš„ŠžĻć┐╔─▄╚┌║ŽĄ┌╚²ĘĮĘ■䚥─╠žš„Ż¼ę╗░ŃĄ┌╚²ĘĮĘ■äšīó«a╔·Ą─╠žš„░┤šš╝sČ©Ą─Ė±╩Į┤µā”į┌HDFS╔ŽĪŻ
ĪĪĪĪöĄō■į┤Įyę╗Ė±╩Į×ķŻ║ poiid/dealid/bizareaid 't' name1:value1't' name2:value2...
ĪĪĪĪ╠žš„║Ž▓ó─ŻēKŻ¼īó╦∙ėąüĒį┤║Ž▓ó×ķę╗éĆ┤¾╬─╝■Ż¼═©▀^feature conf┼õų├Ą─╠žš„║═╠žš„Ēśą“Ż¼īó╠žš„ą“┴ą╗»Ż¼╚╗║¾īæ╚ļHive▒ĒĪŻ
ĪĪĪĪ╠žš„▒O┐ž─ŻēK├┐╠ņ▒O┐ž╠žš„Ą─Ęų▓╝Ą╚╩Ūʱ«É│ŻĪŻ ╠žš„ŠžĻćĄ─╠žš„├┐╚šĖ³ą┬ĪŻ
ĪĪĪĪ╠Ē╝ėą┬Ą─╠žš„üĒį┤Ż¼ų╗ąĶę¬░┤šš╝sČ©Ą─Ė±╩Į╔·│╔öĄō■į┤Ż¼┼õų├┬ĘÅĮŻ¼┐╔ūįäė╠Ē╝ėĪŻ
ĪĪĪĪ╠Ē╝ėą┬╠žš„Ż¼į┌feature conf╬─╝■─®╬▓╠Ē╝ėŽÓæ¬Ą─╠žš„├¹Ż¼╠žš„├¹ūų║═öĄō■į┤ųąĄ─╠žš„name▒Ż│ųę╗ų┬Ż¼ūŅ║¾ą▐Ė─ŽÓæ¬Ą─╠žš„Hive▒ĒĮYśŗĪŻ
ĪĪĪĪ╠žš„ŠžĻćĄ─╩╣ė├
ĪĪĪĪ╠žš„ŠžĻćĄ─╩╣ė├┐“╝▄×ķŻ║
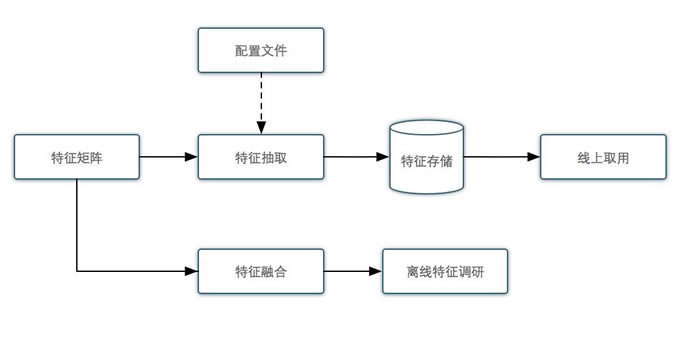
ĪĪĪĪ╬ęéāüĒįö╝Üšf├„ę╗Ž┬┴„│╠ĪŻ
ĪĪĪĪŲõųą╠žš„ŠžĻć╝╚╠ß╣®į┌ŠĆĄ─╠žš„é}ÄņŻ¼ėų┐╔╠ß╣®ļxŠĆĄ─╠žš„š{čąĪŻŠĆ╔ŽĘ■äšąĶę¬┤¾┴┐Ą─╠žš„üĒī”POI/DEAL┘|┴┐┤“ĘųŻ¼╠žš„Ęų╔óĢ■įņ│╔Ę■äš╚Īė├╠žš„║▄║─ĢrŻ¼╠žš„ŠžĻćīó╠žš„š¹║ŽŻ¼║▄║├Ą─ĮŌøQ┴╦╠žš„║─ĢrĄ─å¢Ņ}ĪŻę╗░Ńš{čąę╗éĆą┬╠žš„ąĶę¬Ęe└█ę╗Č╬ĢrķgĄ─öĄō■Ż¼īó╠žš„Ę┼╚ļ╠žš„ŠžĻćŻ¼
ĪĪĪĪ╚╗║¾║═ęčėąĄ─öĄō■▀Mąą╚┌║ŽŻ¼┐╔ĘĮ▒ŃĄ─śŗįņ░³║¼ą┬╠žš„Ą─ė¢ŠÜöĄō■ĪŻŽ┬├µ╬ęéāĘųäeüĒ┐┤ę╗Ž┬į┌ŠĆĪóļxŠĆ║═╠žš„╚┌║ŽĄ─┴„│╠ĪŻ
ĪĪĪĪį┌ŠĆ╩╣ė├
ĪĪĪĪį┌ŠĆĘĮ├µĄ─╩╣ė├ų„ę¬╩ŪĘĮ▒Ń╠žš„Ą─½@╚ĪŻ¼īóŠĆ╔ŽąĶꬥ─╠žš„╝{╚ļ╠žš„ŠžĻćĮyę╗╣▄└ĒŻ¼═©▀^┼õų├╬─╝■ūx╚Ī╠žš„ŠžĻćĄ─╠žš„Ż¼ĘŌčb│╔Proto Buffersīæ╚ļMedis(├└łFūįų„śŗĮ©Ą─Redis╝»╚║Ż¼ų¦│ųĘų▓╝╩Į║═╚▌Õe)Ż¼═©▀^Medis key┼·┴┐ūx╚Īįōkeyī”æ¬Ą─╠žš„Ż¼£p╔┘ūx╚ĪMedisĄ─┤╬öĄŻ¼Å─Č°┐s£p╠žš„½@╚ĪĄ─ĢrķgŻ¼╠ßĖ▀ŽĄĮyĄ─ąį─▄ĪŻ
ĪĪĪĪ╠žš„ŠžĻćį┌ŠĆ╩╣ė├┐“╝▄╚ńŽ┬Ż║
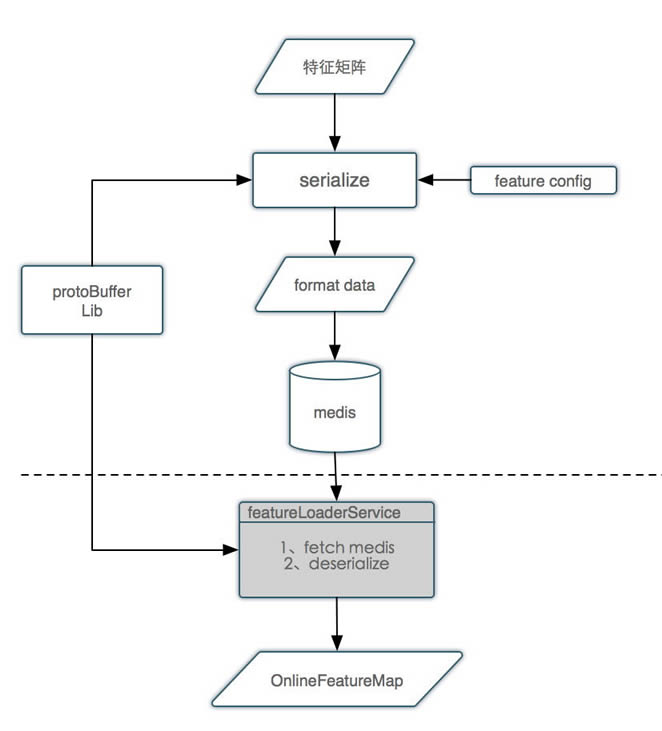
ĪĪĪĪ┴„│╠šf├„Ż║
ĪĪĪĪą“┴ą╗»─ŻēK═©▀^╠žš„┼õų├╬─╝■Å─╠žš„ŠžĻć│ķ╚ĪąĶꬥ─╠žš„Ż¼š{ė├protoBuffer Libīó╠žš„ĘŌčb│╔protoBufferĄ─Ė±╩ĮŻ¼īæ╚ļMedisĪŻ
ĪĪĪĪŠĆ╔Ž═©▀^featureLoaderĘ■äšÅ─Medisūx╚ĪöĄō■Ż¼╚╗║¾═©▀^protoBufferLibĘ┤ą“┴ą╗»öĄō■Ż¼╚ĪĄĮŽÓæ¬Ą─╠žš„ųĄĪŻ
ĪĪĪĪļxŠĆ╩╣ė├
ĪĪĪĪļxŠĆĘĮ├µĄ─╩╣ė├ų„ę¬╩ŪĘĮ▒Ńš{čąą┬╠žš„ĪŻ╚ń╣¹Å─ŠĆ╔Ž½@╚Īą┬╠žš„Ż¼ė╔ė┌ąĶę¬Ęe└█ė¢ŠÜöĄō■Ż¼╠žš„š{蹥─ų▄Ų┌Ģ■ūāķL;Č°╚ń╣¹īó┤²š{蹥─╠žš„╝{╚ļ╠žš„ŠžĻćųąŻ¼┐╔ęį║▄ĘĮ▒ŃĄž═©▀^ļxŠĆĄ─ĘĮĘ©š{čą╠žš„Ą─ėąą¦ąįŻ¼śO┤¾Ą─┐sČ╠┴╦╠žš„š{蹥─ų▄Ų┌Ż¼╠ßĖ▀ķ_░lą¦┬╩║═─Żą═Ą³┤·Ą─╦┘Č╚ĪŻ
ĪĪĪĪ╠žš„ŠžĻćļxŠĆ╩╣ė├┐“╝▄╚ńŽ┬Ż║
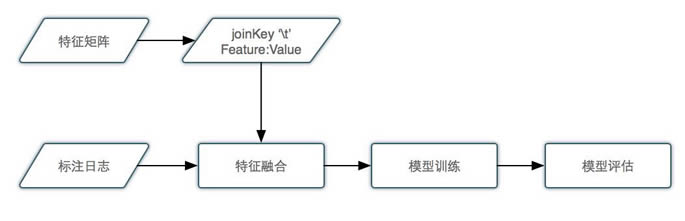
ĪĪĪĪŲõųąŻ¼Å─╠žš„ŠžĻć╚Ī│÷┤²š{蹥─ą┬╠žš„Ż¼Ė±╩Į╗»×ķ joinKey 't' FeatureName:FeatureValueŻ¼ └²╚ń 12345 't' CTR:0.123Ż¼joinkey×ķpoiid, ą┬╠žš„×ķCTRŻ¼╠žš„ųĄ×ķ0.123ĪŻĖ±╩Į╗»║¾Ą─ą┬╠žš„╬─╝■║═ś╦ūó║├Ą─rerank╚šųŠū„×ķ▌ö╚ļŻ¼Įø▀^Map/Reduce╠Ä└Ē╔·│╔ą┬Ą─ś╦ūó╚šųŠŻ¼ė├ė┌─Żą═ė¢ŠÜĪŻ
ĪĪĪĪ╠žš„╚┌║Ž
ĪĪĪĪ╠žš„╚┌║Žū„ė├ė┌ļxŠĆ╠žš„š{蹯¼╔ŽŲ¬╬ęéā╠ߥĮöĄō■ś╦£╩Ģ■▌ö│÷ōĒėąžSĖ╗╠žš„Ą─ś╦ūó╚šųŠŻ¼╠žš„╚┌║ŽĄ──┐Ą─į┌ė┌īó┤²š{蹥─ą┬╠žš„═©▀^─│ę╗éĆjoinkey ║Ž▓óĄĮį┌ŠĆ╠žš„┴ą▒ĒųąŻ¼Å─Č°į┌─Żą═ė¢ŠÜųą╩╣ė├įō╠žš„ĪŻ
ĪĪĪĪ╠žš„╚┌║ŽĄ─┐“╝▄Ż║
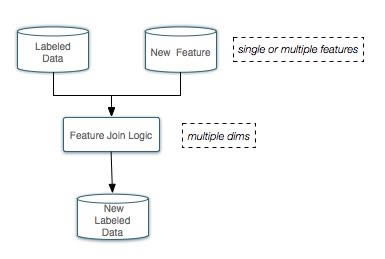
ĪĪĪĪ┴„│╠šf├„Ż║ ╠žš„╚┌║Ž─ŻēK┐╔ęįųĖČ©╚╬ęŌę╗éĆ╗“š▀ČÓéĆjoin keyŻ¼īóļxŠĆ╠žš„╝ė╚ļį┌ŠĆ╠žš„┴ą▒ĒĪŻ
ĪĪĪĪ▒O┐žŽĄĮy
ĪĪĪĪ▒O┐žŽĄĮyĄ──┐Ą─╩Ū┤_▒Żį┌ŠĆ║═ļxŠĆ╚╬䚥─š²│Ż▀\ąąĪŻ▒O┐žŽĄĮy░┤ššū„ė├ĘČć·Ą─▓╗═¼ėųĘų×ķŠĆ╔Ž▒O┐ž║═ļxŠĆ▒O┐žĪŻ
ĪĪĪĪŠĆ╔Ž▒O┐ž
ĪĪĪĪŠĆ╔Ž▒O┐žų„ę¬╩Ū▒O£y╩š╝»Ą─į┌ŠĆ╠žš„╚šųŠ╩Ūʱš²│ŻŻ¼ŠĆ╔Ž╠žš„▒O┐žų„ę¬Öz£y╠žš„Ą─Ė▓╔wČ╚ĪóķōųĄĘČć·ĪóĘų▓╝«É│Ż╚²ĘĮ├µĪŻ
ĪĪĪĪ╚²ĘĮ├µĄ─▒O┐žų„ę¬ĘųęįŽ┬ÄūéĆł÷Š░Ż║
ĪĪĪĪĖ▓╔wČ╚Ż║▒O┐ž╠žš„Ą─öĄō■į┤╩Ūʱ┤µį┌╗“š▀ėąöĄō■üG╩¦ĪŻ
ĪĪĪĪķōųĄĘČć·Ż║▒O┐ž╠žš„Ą─ķōųĄ╩ŪĘ±Ę¹║ŽŅAŲ┌Ż¼Ę└ų╣ę“×ķ╔·│╔╠žš„Ą─╦ŃĘ©Ė─ūā╗“š▀į┌ŠĆėŗ╦ŃĘĮĘ©Ą─▓╗═¼Ą╚ę“╦žįņ│╔╠žš„Ą─ūŅ┤¾ųĄ╗“š▀ūŅąĪųĄ░l╔·▒╚▌^├„’@Ą─ūā╗»Ż¼ī¦ų┬╠žš„▓╗┐╔ė├ĪŻ
ĪĪĪĪĘų▓╝«É│ŻŻ║▒O┐ž╠žš„ųĄĄ─Ęų▓╝╩ŪĘ±Ę¹║ŽŅAŲ┌Ż¼ų„ę¬Ę└ų╣ę“×ķ½@╚Ī▓╗ĄĮ╠žš„Ż¼╩╣Ą├╠žš„Č╝╩╣ė├┴╦─¼šJųĄŻ¼Č°ėųø]ėą╝░Ģr░l¼FŻ¼ī¦ų┬ŠĆ╔Ž─Żą═ŅA╣└│÷¼FŲ½▓ŅĪŻĘų▓╝«É│Żų„ę¬ė├ĄĮ┴╦┐©ĘĮŠÓļx[3]ĪŻ
ĪĪĪĪ╠žš„Ė▓╔wČ╚▒O┐žą¦╣¹łDŻ║
ĪĪĪĪŽ┬łD╩Ūė├æ¶ĄĮPOIŠÓļxĄ─Ė▓╔wČ╚▒O┐žĪŻÅ─łDųą┐╔ęįų▒ė^Ą─┐┤│÷Ż¼įō╠žš„Ą─Ė▓╔wČ╚╝s×ķ75%Ż¼ę▓╝┤ų╗ėą75%Ą─ė├æ¶─▄Ą├ĄĮŠÓļx╠žš„Ż¼┴Ē═Ō25%┐╔─▄ø]ėąķ_╩ųÖCČ©╬╗Ę■äš╗“š▀Ą├▓╗ĄĮPOIĄ─ū°ś╦ĪŻ75%Ą─Ė▓╔wČ╚╩Ūę╗éĆ▒╚▌^ĘĆČ©Ą─ųĖś╦Ż¼╚ń╣¹Ė▓╔wČ╚ūāĄ─║▄Ė▀╗“š▀║▄Ą═Č╝šf├„╬ęéāĄ─ŽĄĮy│÷¼F┴╦å¢Ņ}Ż¼Č°╬ęéāĄ─▒O┐žŽĄĮy─▄╝░Ģr░l¼F▀@ĘNå¢Ņ}ĪŻ
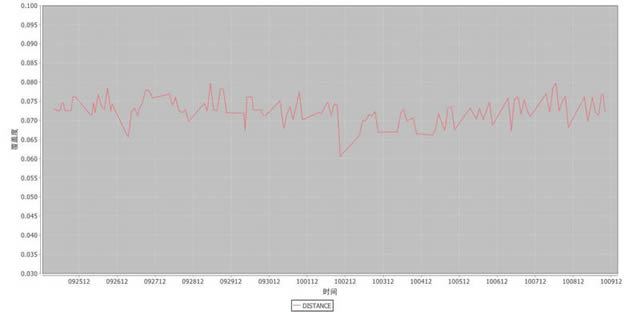
ĪĪĪĪļxŠĆ▒O┐ž
ĪĪĪĪļxŠĆ▒O┐žų„ę¬Öz£yā╔ĘĮ├µŻ║1ĪóļxŠĆ╚╬äš╩Ūʱ░┤Ģr═Ļ│╔╝░╔·│╔Ą─öĄō■╩Ūʱš²┤_ĪŻ 2Īó╠žš„ŠžĻć╠žš„Ą─ėąą¦ąįĪŻ
ĪĪĪĪ«öļxŠĆČ©Ģr╚╬äšČÓ▀_öĄ╩«éĆĄ─Ģr║“Ż¼║▄ļy├┐╠ņ╚źųéĆÖz▓ķ├┐éĆ╚╬äš╩Ūʱ╚ńŲ┌═Ļ│╔Ż¼▀@Ģr║“ļxŠĆ╚╬äš▒O┐žĄ─ųžę¬ąįŠ══╣’@│÷üĒĪŻ«öŪ░ļxŠĆ▒O┐ž┐╔ęįĖ∙ō■┼õų├╬─╝■Ż¼▒O┐žąĶę¬ĻPūóĄ─╚╬䚯¼ęį╝░▀@ą®╚╬äš╔·│╔Ą─öĄō■╩Ūʱš²│ŻĪŻ╚ń╣¹▓╗š²│Żät░l│÷ł¾Š»Įo╚╬äšžōž¤╚╦Ż¼▀_ĄĮ╚╬äš╩¦öĪ─▄ē“╝░Ģr╠Ä└ĒĄ──┐Ą─ĪŻ
ĪĪĪĪ╠žš„ŠžĻć▒O┐žĄ──┐Ą─┼cį┌ŠĆ╠žš„Ą─▒O┐ž─┐Ą─ę╗śėŻ¼▒O┐žųĖś╦ę▓ŽÓ═¼Ż¼╦∙▓╗═¼Ą─╩Ūę“×ķ▒O┐žöĄō■Ą─½@╚Ī▓╗═¼Ż¼▒O┐žīŹ¼Fę▓▓╗▒MŽÓ═¼Ż¼▀@└’▓╗į┘┘ś╩÷ĪŻ
ĪĪĪĪ─Żą═š{čą
ĪĪĪĪ─Żą═ė¢ŠÜ
ĪĪĪĪ─Żą═ė¢ŠÜ┐“╝▄ų¦│ųČÓĘN─Żą═Ą─ė¢ŠÜŻ¼īóė¢ŠÜöĄō■Ė±╩Į╗»×ķ─Żą═ąĶꬥ─▌ö╚ļĖ±╩ĮĪŻą▐Ė──Żą═ė¢ŠÜĄ─┼õų├╬─╝■Ż¼Š═┐╔ęį╩╣ė├įō┐“╝▄ė¢ŠÜ─Żą═┴╦ĪŻ
ĪĪĪĪ─Żą═ė¢ŠÜ┐“╝▄Ż║
ĪĪĪĪŲõųąŻ¼Ēöīė╩Ūė¢ŠÜöĄō■║═£yįćöĄō■Ą─▌ö╚ļīėŻ¼įōīė╩ŪįŁ╩╝ė¢ŠÜ║═£yįćöĄō■ĪŻ
ĪĪĪĪųąķg╩Ū─Żą═ė¢ŠÜĄ─┐“╝▄Ż¼┐“╝▄ų¦│ųČÓéĆ┼õų├ĒŚŻ¼░³└©┼õų├─Żą═╦ŃĘ©ĪóŽÓæ¬Ą─ģóöĄĪóöĄō■į┤Ą─▌ö╚ļ╝░─Żą═Ą─▌ö│÷Ą╚ĪŻ
ĪĪĪĪĄūīė╩ŪČÓĘN─Żą═Ą─īŹ¼FŻ¼╦ŃĘ©ų«Ū░ŽÓ╗ź¬Ü┴óŻ¼├┐ĘN╦ŃĘ©ĘŌčb│╔¬Ü┴óĄ─jarŻ¼╠ß╣®Įo─Żą═ė¢ŠÜ┐“╝▄╩╣ė├Ż¼─┐Ū░ų¦│ųĄ─╦ŃĘ©░³└©GBDT[4]ĪóFTRL[5]ĪŻ
ĪĪĪĪ×ķ┴╦īŹ¼F─Żą═Ą─┐ņ╦┘Ą³┤·Ż¼─Żą═ė¢ŠÜų¦│ųį┌Spark╔Ž▀\ąąĪŻ
ĪĪĪĪą¦╣¹įu╣└
ĪĪĪĪ─Żą═Ą─ą¦╣¹įu╣└ų„ę¬╩Ūī”▒╚ą┬─Żą═║═└Ž─Żą═Ą─ą¦╣¹Ż¼ęįįu╣└ĮY╣¹üĒøQČ©╩ŪʱĖ³ą┬ŠĆ╔Ž─Żą═ĪŻ
ĪĪĪĪ╬ęéāĄ─ŽĄĮyų¦│ųā╔ĘNą¦╣¹ųĖś╦Ą─įu╣└Ż¼ę╗ĘN╩ŪAUC[1]Ż¼┴Ēę╗ĘN╩ŪMAPĪŻ
ĪĪĪĪMAP(Mean Average Precision)[2]╩Ūę╗ĘNī”╦č╦„┼┼ą“ĮY╣¹║├ē─įu╣└Ą─ųĖś╦ĪŻ
ĪĪĪĪPrec@K Ą─Č©┴xŻ║ įOČ©ķōųĄKŻ¼ėŗ╦Ń┼┼ą“ĮY╣¹topKĄ─ŽÓĻPČ╚ĪŻ
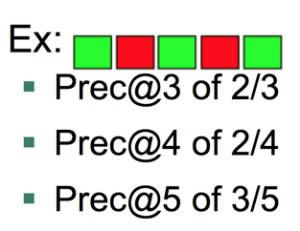
ĪĪĪĪūóŻ║ŠG╔½▒Ē╩Š╦č╦„ĮY╣¹┼c╦č╦„į~ŽÓĻPŻ¼╝t╔½▒Ē╩Š▓╗ŽÓĻPĪŻ
ĪĪĪĪAP(Average Precision)Ą─Č©┴xŻ║ Average Precision = average of Prec@K

ĪĪĪĪAPū„×ķ┼┼ą“║├ē─Ą─ų▒ė^└ĒĮŌ

ĪĪĪĪ╗ę╔½▒Ē╩Š┼c╦č╦„ŽÓĻPĄ─ĮY╣¹Ż¼į┌łF┘Åųą▒Ē╩Š▒╗³cō¶Ą─DEALŻ¼Å─š┘╗žĮY╣¹┐┤Ranking#1ę¬║├ė┌Ranking#2Ż¼Ę┤ė│į┌MAPųĖś╦╔ŽŻ¼Ranking#1Ą─MAPųĄ┤¾ė┌Ranking#2Ą─MAPųĄĪŻ
ĪĪĪĪ╦∙ęį┐╔ęį║åå╬Ąž╩╣ė├APųĄüĒ║Ō┴┐─Żą═┼┼ą“Ą─║├ē─ĪŻ
ĪĪĪĪMAPĄ─ėŗ╦Ń
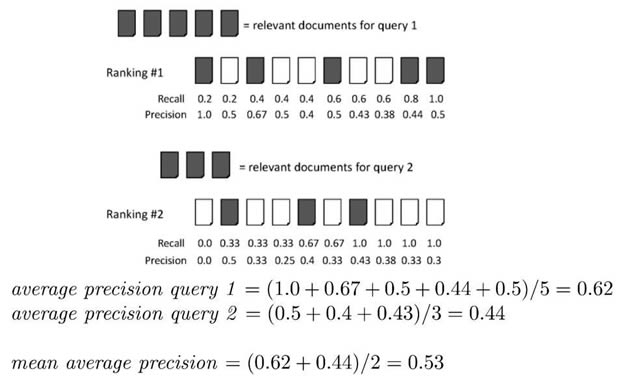
ĪĪĪĪī”ė┌ČÓéĆqueryĄ─╦č╦„ĮY╣¹Ż¼MAP×ķ▀@ą®╦č╦„ĮY╣¹APĄ─Š∙ųĄĪŻ
ĪĪĪĪīŹ“×ĮY╣¹▒Ē├„MAPū„×ķ┼┼ą“ųĖś╦Ż¼ī”─Żą═║├ē─Ą─įu╣└ŲĄĮ║▄║├Ą─ųĖī¦ū„ė├ĪŻ
ĪĪĪĪį┌AUCĄ─Į³╦Ųėŗ╦ŃĘĮĘ©ųąŻ¼ų„ę¬┐╝æ]ėąČÓ╔┘ī”š²žōśė▒ŠĮM║Žųąš²śė▒ŠĄ─Ą├Ęų┤¾ė┌žōśė▒ŠĄ─Ą├ĘųŻ¼┼cš²śė▒Šį┌┼┼ą“ųąĄ─Š▀¾w╬╗ų├ø]ėąĮ^ī”Ą─ĻPŽĄĪŻ«öš²žōśė▒ŠĄ─Ęų▓╝ūā╗»Ż¼╚ń─│ę╗ąĪ▓┐Ęųš²śė▒ŠĄ├Ęųūā┤¾Ż¼┤¾▓┐Ęųš²śė▒ŠĄ├ĘųūāąĪŻ¼─Ū├┤ūŅĮKėŗ╦ŃĄ─AUCųĄ┐╔─▄ø]ėą░l╔·ūā╗»Ż¼Ą½┼┼ą“Ą─ĮY╣¹ģs░l╔·┴╦║▄┤¾ūā╗»(┤¾▓┐Ęųė├æ¶Ėą┼d╚żĄ─å╬ūė┼┼į┌┴╦║¾▀ģ)ĪŻ
ĪĪĪĪę“┤╦AUCųĖś╦ø]Ę©ų▒ė^įu╣└╚╦ī”┼┼ą“║├ē─Ą─Ėą╩▄ĪŻ
╦č╦„ę²Ūµā×╗»į┌ć°═Ō░lš╣čĖ╦┘Ż¼ć°ā╚ę▓ėą▒ŖČÓĄ─ā×╗»É█║├š▀ĪŻ═©▀^┴╦ĮŌĖ„ŅÉ╦č╦„ę²Ūµūź╚Ī╗ź┬ōŠWĒō├µĪó▀Mąą╦„ę²ęį╝░┤_Č©Ųõī”╠žČ©ĻPµIį~╦č╦„ĮY╣¹┼┼├¹Ą╚╝╝ągŻ¼üĒī”ŠWĒō▀MąąŽÓĻPĄ─ā×╗»Ż¼╩╣Ųõ╠ßĖ▀╦č╦„ę²Ūµ┼┼├¹ĪŻ
