╔ąĢ°Ų▀╠¢ocr╩Ūę╗┐Ņ▓┘ū„║åå╬Īó╣”─▄║åå╬Ą─╬─ūųūRäeŽĄĮyŻ¼ūRäe─▄┴”Ė▀Ż¼╦┘Č╚┐ņŻ¼ų╗ąĶīó╝ł┘|╬─ÖnÆ▀├ĶŻ¼╔ąĢ°Ų▀╠¢ocrŠ═─▄īóŲõųąĄ─╬─ūų╠ß╚Ī│÷üĒŻ¼ØMūŃĢ°╝«Īół¾┐»ļsųŠĪół¾▒ĒŲ▒ō■Īó╣½╬─Ön░ĖĄ╚õø╚ļĪŻ ─┐Ū░Ż¼įSČÓą┼Žó┘Y┴ŽąĶę¬▐D╗»│╔ļŖūė╬─Önęį▒Ńė┌Ė„ĘNæ¬ė├╝░╣▄└ĒŻ¼Ą½ę“ą┼ŽóöĄūų╗»╠Ä└ĒĄ─ĘĮ╩Į┬õ║¾ĪŻ▓╗Ą½┘MĢr┘M┴”Ż¼Č°Ūę┘YĮ║─┘MŠ▐┤¾Ż¼įņ│╔┴╦┤¾┴┐╬─Ön┘Y┴ŽĄ─Ęeē║Ż¼Č°╔ąĢ°Ų▀╠¢ocr─▄ē“ØMūŃ▀@ĘN║Ż┴┐õø╚ļąĶŪ¾ĪŻ
1.ĄĮ▒ŠšŠŽ┬▌d░▓čb╔ąĢ°Ų▀╠¢ocrŻ¼┤“ķ_░▓čb│╠ą“Ż¼³cō¶Ž┬ę╗▓Į└^└m░▓čb
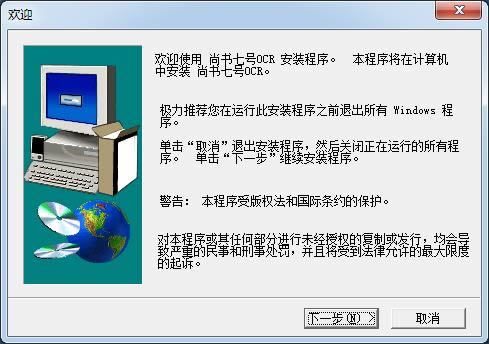
2.─¼šJą┼ŽóŻ¼ų▒ĮėŽ┬ę╗▓Į
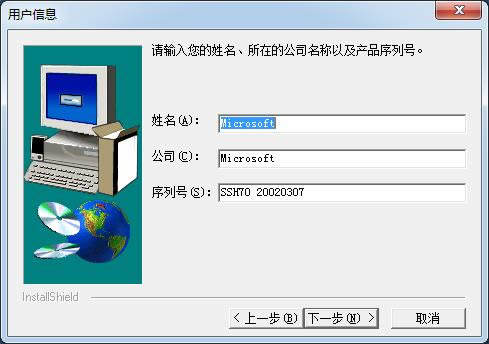
3.³cō¶×gė[▀xō±░▓čb╬╗ų├
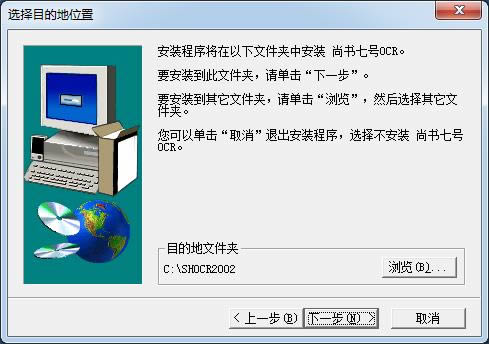
4.ūŅ║¾³cō¶═Ļ│╔╝┤┐╔Ż¼▄ø╝■░▓čb═Ļ«ģ
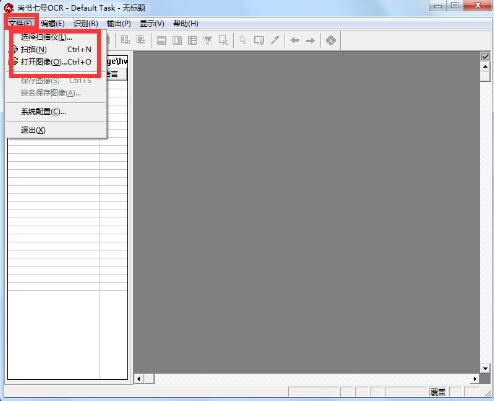
▓Į¾E1Ż║½@╚Ī╬─ūųłDŽ±╬─╝■ĪŻ
▀xō±“╬─╝■”▓╦å╬Ž┬Ą─“Æ▀├Ķ”╗““┤“ķ_łDŽ±”Ż©īóęčĮøÆ▀├Ķ║├Ą─łDŽ±╬─╝■┤“ķ_Ż®├³┴ŅŻ¼┤“ķ_łDŽ±╬─╝■ĪŻ╚ń╣¹▀BĮė┴╦ČÓ┼_Æ▀├ĶāxŻ¼┐╔ęį▀xō±“╬─╝■”▓╦å╬Ž┬Ą─“▀xō±Æ▀├Ķāx”├³┴ŅŻ¼š{ė├Æ▀├ĶāxĪŻ
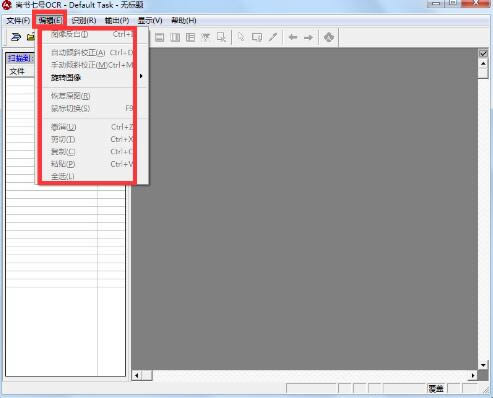
▓Į¾E2Ż║ī”Æ▀├ĶĄ─łDŽ±Ēō▀Mąąš{š¹
▀xō±“ŠÄ▌ŗ”▓╦å╬Ž┬“łDŽ±Ēō├µĄ─╠Ä└Ē”ūė▓╦å╬Ž┬Ą─“łDŽ±ĒōĄ─āAą▒ąŻš²”Ż©╠ß╣®ūįäė║═╩ųäėīŹ¼FĘĮĘ©Ż®╝░“ą²▐D”Ą╚├³┴ŅŻ¼īóÆ▀├ĶĄ─łDŽ±Ēō▀Mąąš{š¹ĪŻ
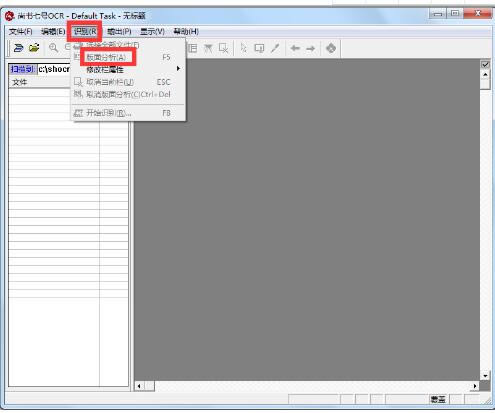
▓Į¾E3Ż║░µ├µĘų╬÷┼c╬─ūųūRäe▐D╗»
░µ├µĘų╬÷Ż¼▀xō±ūRäeĘČć·Ż¼į┌▀Mąą╬─ūųūRäeŪ░ę¬▀xō±ūRäeĘČć·Ż¼ūRäe▀^│╠Ą─║╦ą─╩Ū“░µ├µĘų╬÷”ĪŻ
╔ąĢ°Ų▀╠¢Ą─ūįäė░µ├µĘų╬÷╣”─▄║▄ÅŖŻ¼ī”ł¾╝łļsųŠĄ╚Å═ļsĄ─░µ├µŻ¼ę▓─▄▒Ż│ų║▄Ė▀Ą─Ęų╬÷š²┤_┬╩ĪŻ
įOų├║├║¾Ż¼ų▒Įė³cō¶“ķ_╩╝ūRäe”Ą─░┤ŌoŠ═┐╔ęį▀Mąą╬─ūųūRäe┴╦ĪŻ
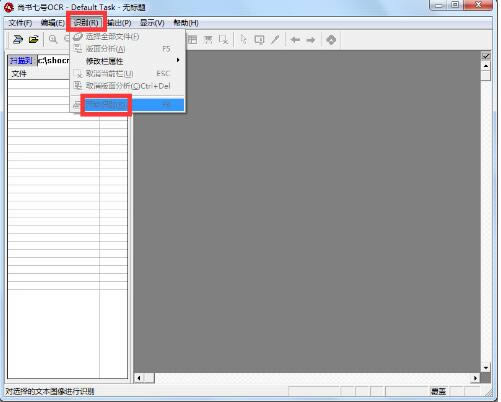
▓Į¾E4Ż║ąŻī”ą▐Ė─
ūįäėūRäe═Ļ«ģŻ¼ūRäeĮY╣¹Ą─“╬─▒Š┤░┐┌”Ģ■ÅŚ│÷Ż¼▀@éĆ┤░┐┌─▄ē“╠ß╣®ūRäeĮY╣¹Ą─ąŻī”Ż¼×ķ┴╦ąŻī”ĘĮ▒ŃŻ¼╔ąĢ°Ų▀╠¢į÷╝ė┴╦╣Ōś╦Ė·ļS’@╩ŠįŁłDŽ±ąąĄ─ąŻī”ĘĮĘ©Ż©╚ńłD3│÷¼FĄ─³S╔½╠ß╩ŠąąĄ─│÷¼FŻ®ĪŻ
╠ß╣®Ą─ąŻī”ĘĮĘ©Ż¼ę╗č█Š═─▄ē“┐┤ĄĮłDŽ±įŁ╬─║═ūRäe│÷╬─▒ŠĄ─▓ŅäeŻ¼╚ń╣¹░l¼FūRäeėąš`Ż¼┐╔ęį▀Mąąą▐Ė─ĪŻ
▓Į¾E5Ż║▌ö│÷
╚ń╣¹Öz▓ķą▐Ė─║¾┤_šJ¤oš`Ż¼▀xō±ūRäeĮY╣¹Ą─“▌ö│÷”▓╦å╬Ż¼▌ö│÷Ą─╬─╝■Ė±╩ĮėąŻ║RTFĪóHTMLĪóXLSĪó22238Ż¼┐╔ęįĖ∙ō■ūį╝║Ą─ąĶę¬▀xō±ī”æ¬Ą─Ė±╩ĮĪŻ╚ń╣¹ė├涎ļĄ├ĄĮŅÉ╦ŲįŁ╬─Ą─ūRäeĮY╣¹Ż¼šł▀xō±RTFĖ±╩ĮĪŻ░čRTFĖ±╩Į▌ö│÷Ą─╬─╝■ė├WORD┤“ķ_║¾Ż¼Ģ■░l¼FÄū║§▒Ż┴¶┴╦įŁ╬─Ą─╦∙ėą║██EŻ¼░³└©įŁüĒĒō├µųąĄ─▓╩╔½łDŽ±Ż¼Č╝ęčĮø▒Ż┴¶į┌WORDųą┴╦ĪŻ
“vėŹęĢŅl╣┘ĘĮ░µ | 45.34MB

“vėŹęĢŅl╩Ū“vėŹŲņŽ┬Ą─ęĢŅl▓źĘ┼«aŲĘŻ¼Č©╬╗ė┌ųąć°ūŅ┤¾į┌ŠĆęĢŅl├Į¾wŲĮ┼_Ż¼ė┌2011─Ļ4į┬š²╩Į╔ŽŠĆ▀\ĀI¬Ü┴óė“├¹Ą─ęĢŅlŠWšŠŻ¼ų¦│ųžSĖ╗ā╚╚▌Ą─į┌ŠĆ³c▓ź╝░ļŖęĢ┼_ų▒▓źŻ¼╠ß╣®┴ą▒Ē╣▄└Ē..
É█Ųµ╦ćęĢŅl╣┘ĘĮš²╩Į░µ | 35.10MB

É█Ųµ╦ćŻ¼įŁ├¹Ųµ╦ćŻ¼ė┌2010─Ļ4į┬22╚šš²╩Į╔ŽŠĆŻ¼2011─Ļ11į┬26╚šŲĘ┼Ų╔²╝ēŻ¼åóäėĪ░É█Ųµ╦ćĪ▒ŲĘ┼Ų▓ó═Ų│÷╚½ą┬ś╦ųŠĪŻÉ█Ųµ╦ćäō╩╝╚╦²ÅėŅ▓®╩┐ō·╚╬CEOĪŻ...
▒®’Lė░ę¶ūŅą┬░µŽ┬▌d | 50.3MB

▒®’Lė░ę¶▓źĘ┼Ą─╬─╝■ŪÕ╬·Ż¼«öėą╬─╝■▓╗┐╔▓źĢrŻ¼ėę╔ŽĮŪĄ─Ī░▓źĪ▒ŲĄĮ┴╦ŪąōQęĢŅlĮŌ┤aŲ„║═ę¶ŅlĮŌ┤aŲ„Ą─╣”─▄Ż¼Ģ■ŪąōQęĢŅlĄ─ūŅ╝č╚²ĘNĮŌ┤aĘĮ╩ĮŻ¼═¼ĢrŻ¼▒®’Lė░ę¶ę▓╩Ūć°╚╦ūŅŽ▓É█Ą─▓źĘ┼Ų„ų«ę╗...
QQ궜Ę╣┘ĘĮš²╩Į░µ | 24.2MB

QQ궜Ę╩Ū“vėŹ╣½╦Š═Ų│÷Ą─ŠWĮj궜ĘŲĮ┼_Ż¼╩Ūųąć°╗ź┬ōŠWŅIė“ŅIŽ╚Ą─š²░µöĄūų궜ĘĘ■䚥─ŅIŽ╚ŲĮ┼_Ż¼ėąų°éĆąį├„ąŪų„Ņ}Ż║┤¾┐¦čbŻ¼╠ĒąŪŖyŻĪ...
┐ß╣Ę궜Ę2022Ž┬▌d | 37MB

┐ß╣Ę╩Ūųąć°ŅIŽ╚Ą─öĄūų궜ĘĮ╗╗źĘ■äš╠ß╣®╔╠Ż¼╗ź┬ōŠW╝╝ągäōą┬Ą─ŅI▄ŖŲ¾śIŻ¼ų┬┴”ė┌×ķ╗ź┬ōŠWė├æ¶║═öĄūų궜ʫaśI░lš╣╠ß╣®ūŅ╝čĄ─ĮŌøQĘĮ░Ė...
┐ß╬ę궜ʎ┬▌d | 47.4MB

┐ß╬ę궜ʥ─Įń├µ║åØŹ┤¾ĘĮŻ¼£\╦{╔½┼c│╚╔½ŽÓķgŻ¼Ę¹║Ž┤¾ČÓöĄė├æ¶Ą─īÅ├└Ž▓║├ĪŻ┤“ķ_┐ß╬ę궜ʯ¼╔Ž▓┐▓╦å╬Ö┌░³└©Ī░╬ęĄ─Ī▒ĪóĪ░═Ų╦]Ī▒ĪóĪ░Ū·ÄņĪ▒ĪóĪ░ęĢŅlĪ▒...