[š¬ę¬]Øh═§ocrūRäe▄ø╝■╩Ūę╗┐ŅĖ▀ą¦īŹė├Ą─╬─ūųūRäe▄ø╝■Ż¼┐ņ╦┘Æ▀├ĶBMP��ĪóTIF�����ĪóJPG���ĪóPDFĄ╚Ė±╩ĮłDŽ±▓ó╠ß╚Ī│÷╬─ūųā╚╚▌Ż¼▌p╦╔īóPDF╬─╝■▐DōQ×ķ┐╔ŠÄ▌ŗĄ─╬─Ön╗“╩ŪTXT╬─▒ŠŻ¼╦┘Č╚┐ņ�����Īó£╩┤_┬╩Ė▀��Ż¼▀Ć─▄ē“Š½£╩ūRäe░┘...
Øh═§ocrūRäe▄ø╝■╩Ūę╗┐ŅĖ▀ą¦īŹė├Ą─╬─ūųūRäe▄ø╝■��Ż¼┐ņ╦┘Æ▀├ĶBMPĪóTIF��ĪóJPG�����ĪóPDFĄ╚Ė±╩ĮłDŽ±▓ó╠ß╚Ī│÷╬─ūųā╚╚▌�����Ż¼▌p╦╔īóPDF╬─╝■▐DōQ×ķ┐╔ŠÄ▌ŗĄ─╬─Ön╗“╩ŪTXT╬─▒ŠŻ¼╦┘Č╚┐ņ��Īó£╩┤_┬╩Ė▀��Ż¼▀Ć─▄ē“Š½£╩ūRäe░┘ėÓĘNėĪ╦óūų¾w║═Ė„ĘNųąėóĘ▒▒ĒłD╗ņ┼┼Ė±╩ĮĄ─╬─▒Š�����ĪŻ▒Š▄ø╝■▀mė├ė┌éĆ╚╦��ĪóąĪą═łDĢ°^ĪóąĪą═Ön░Ė^�����ĪóąĪą═Ų¾śI▀Mąą┤¾ęÄ─Ż╬─Ön▌ö╚ļ���ĪółDĢ°ĘŁėĪ��Īó┤¾┴┐┘Y┴ŽļŖūė╗»Ą─▄ø╝■ŽĄĮyĪŻ
Øh═§ocr╬─ūųūRäe▄ø╝■╣”─▄
1���ĪółDŽ±▌ö╚ļĪóŅA╠Ä└ĒŻ║
łDŽ±▌ö╚ļŻ║ī”ė┌▓╗═¼Ą─łDŽ±Ė±╩Į��Ż¼ėąų°▓╗═¼Ą─┤µā”Ė±╩Į�����Ż¼▓╗═¼Ą─ē║┐sĘĮ╩Į��ĪŻŅA╠Ä└ĒŻ║ų„ę¬░³└©Č■ųĄ╗»Īóįļ┬Ģ╚ź│²��ĪóāAą▒▌^š²Ą╚���ĪŻ
2���ĪóČ■ųĄ╗»Ż║
ī”özŽ±Ņ^┼─özĄ─łDŲ¼�����Ż¼┤¾ČÓöĄ╩Ū▓╩╔½łDŽ±��Ż¼▓╩╔½łDŽ±╦∙║¼ą┼Žó┴┐Š▐┤¾Ż¼ī”ė┌łDŲ¼Ą─ā╚╚▌Ż¼╬ęéā┐╔ęį║åå╬Ą─Ęų×ķŪ░Š░┼c▒│Š░��Ż¼×ķ┴╦ūīėŗ╦ŃÖCĖ³┐ņĄ─���Ż¼Ė³║├Ą─ūRäe╬─ūų���Ż¼╬ęéāąĶꬎ╚ī”▓╩╔½łD▀Mąą╠Ä└Ē��Ż¼╩╣łDŲ¼ų╗Ū░Š░ą┼Žó┼c▒│Š░ą┼ŽóŻ¼┐╔ęį║åå╬Ą─Č©┴xŪ░Š░ą┼Žó×ķ║┌╔½Ż¼▒│Š░ą┼Žó×ķ░ū╔½�����Ż¼▀@Š═╩ŪČ■ųĄ╗»łD┴╦��ĪŻ
3���Īóįļ┬Ģ╚ź│²Ż║
ī”ė┌▓╗═¼Ą─╬─Ön��Ż¼╬ęéāī”į’┬ĢĄ─Č©┴x┐╔ęį▓╗═¼Ż¼Ė∙ō■į’┬ĢĄ─╠žš„▀Mąą╚źį’���Ż¼Š═Įąū÷įļ┬Ģ╚ź│²
4ĪóāAą▒▌^š²Ż║
ė╔ė┌ę╗░Ńė├æ¶���Ż¼į┌┼─šš╬─ÖnĢrŻ¼Č╝▒╚▌^ļSęŌ��Ż¼ę“┤╦┼─šš│÷üĒĄ─łDŲ¼▓╗┐╔▒▄├ŌĄ─«a╔·āAą▒�����Ż¼▀@Š═ąĶę¬╬─ūųūRäe▄ø╝■▀Mąą▌^š²�����ĪŻ
5Īó░µ├µĘų╬÷Ż║
īó╬─ÖnłDŲ¼ĘųČ╬┬õŻ¼ĘųąąĄ─▀^│╠Š═Įąū÷░µ├µĘų╬÷Ż¼ė╔ė┌īŹļH╬─ÖnĄ─ČÓśėąį���Ż¼Å═ļsąįŻ¼ę“┤╦Ż¼─┐Ū░▀Ćø]ėąę╗éĆ╣╠Č©Ą─��Ż¼ūŅāץ─ŪąĖŅ─Żą═��ĪŻ
6�����ĪóūųĘ¹ŪąĖŅŻ║
ė╔ė┌┼─ššŚl╝■Ą─Ž▐ųŲŻ¼Įø│Żįņ│╔ūųĘ¹š│▀B���Ż¼öÓ╣PŻ¼ę“┤╦śO┤¾Ž▐ųŲ┴╦ūRäeŽĄĮyĄ─ąį─▄���Ż¼▀@Š═ąĶę¬╬─ūųūRäe▄ø╝■ėąūųĘ¹ŪąĖŅ╣”─▄ĪŻ
7�����ĪóūųĘ¹ūRäeŻ║
▀@ę╗蹊┐��Ż¼ęčĮø╩Ū║▄įńĄ─╩┬Ūķ┴╦��Ż¼▒╚▌^įńėą─Ż░ÕŲź┼õŻ¼║¾üĒęį╠žš„╠ß╚Ī×ķų„��Ż¼ė╔ė┌╬─ūųĄ─╬╗ęŲ��Ż¼╣P«ŗĄ─┤ų╝Ü���Ż¼öÓ╣P�����Ż¼š│▀BŻ¼ą²▐DĄ╚ę“╦žĄ─ė░Ēæ��Ż¼śO┤¾ė░Ēæ╠žš„Ą─╠ß╚ĪĄ─ļyČ╚���ĪŻ
8�����Īó░µ├µ╗ųÅ═Ż║
╚╦éāŽŻ═¹ūRäe║¾Ą─╬─ūųŻ¼╚į╚╗Ž±įŁ╬─ÖnłDŲ¼─Ūśė┼┼┴ąų°��Ż¼Č╬┬õ▓╗ūā���Ż¼╬╗ų├▓╗ūā�����Ż¼Ēśą“▓╗ūā�����Ż¼Ą─▌ö│÷ĄĮword╬─Ön,pdf╬─ÖnĄ╚Ż¼▀@ę╗▀^│╠Š═Įąū÷░µ├µ╗ųÅ═ĪŻ
9���Īó║¾╠Ä└ĒĪóąŻī”Ż║
Ė∙ō■╠žČ©Ą─šZčį╔ŽŽ┬╬─Ą─ĻPŽĄŻ¼ī”ūRäeĮY╣¹▀Mąą▌^š²Ż¼Š═╩Ū║¾╠Ä└Ē�����ĪŻ
Øh═§ocrūRäe▄ø╝■ų„ę¬╠ž╔½
Øh═§PDF OCRūRäeš²┤_┬╩Ė▀���Ż¼ūRäe╦┘Č╚┐ņ��Īó┼·┴┐╠Ä└Ē╣”─▄��Ż╗
ų¦│ų╠Ä└Ē╗ęČ╚Īó▓╩╔½�����Īó║┌░ū╚²ĘN╔½▓╩Ą─BMP�����ĪóTIFĪóJPG�����ĪóPDFČÓĘNĖ±╩ĮĄ─łDŽ±╬─╝■Ż╗
Øh═§PDF OCR┐╔ūRäe║å¾wĪóĘ▒¾w║═ėó╬─╚²ĘNšZčįŻ╗
Øh═§PDF OCRŠ▀ėą║åå╬ęūė├Ą─▒ĒĖ±ūRäe╣”─▄���Ż╗
Š▀ėąTXTĪóRTFĪóHTM║═XLSČÓĘN▌ö│÷Ė±╩Į���Ż¼▓óėą╦∙ęŖ╝┤╦∙Ą├Ą─░µ├µ▀ĆįŁ╣”─▄ĪŻ
Øh═§ocrūRäe▄ø╝■┐ņĮ▌µI
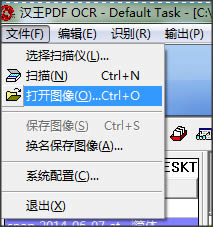
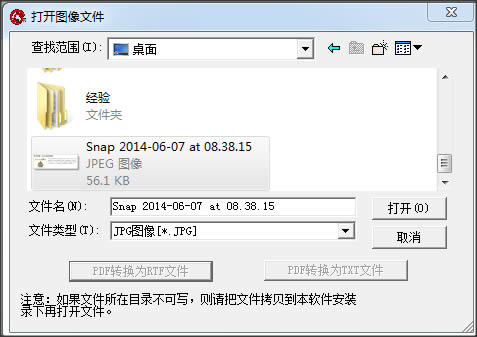
Æ▀├Ķ╬─╝■Ż║ ░┤Ž┬“Ctrl+N”š{│÷Æ▀├Ķ│╠ą“Ż¼Æ▀├ĶłDŽ±╬─╝■�����ĪŻ
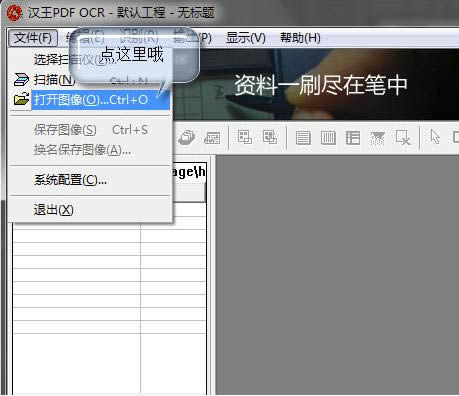
┤“ķ_╬─╝■Ż║ ░┤Ž┬“Ctrl+O”┤“ķ_łDŽ±╬─╝■��Ż¼ūĘ╝ėłDŽ±╬─╝■�����ĪŻ
▒Ż┤µłDŽ±Ż║ ░┤Ž┬“Ctrl+S”µI▒Ż┤µłDŽ±ĪŻ
łDŽ±Ę┤░ūŻ║ ░┤Ž┬“Ctrl+I”īółDŽ±Ę┤░ū���ĪŻ
ūįäėāAą▒ąŻš²Ż║ ░┤Ž┬“Ctrl+D”▀MąąūįäėāAą▒ąŻš²ĪŻ
╩ųäėāAą▒ąŻš²Ż║ ░┤Ž┬“Ctrl+M”▀Mąą╩ųäėāAą▒ąŻš²�����ĪŻ
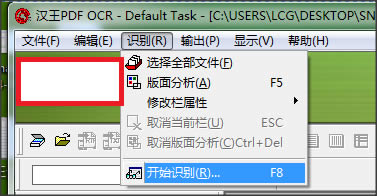
░µ├µĘų╬÷Ż║ ░┤Ž┬“F5”µI��Ż¼ī”▀xųąĄ─╬─╝■▀Mąą░µ├µĘų╬÷�����ĪŻ
╚ĪŽ¹░µ├µĘų╬÷Ż║ ░┤Ž┬“Ctrl+Del”µI���Ż¼╚ĪŽ¹«öŪ░ĒōĄ─░µ├µĘų╬÷���ĪŻ
Øh═§ocrūRäe▄ø╝■░▓čbšf├„
Ž┬▌dØh═§ocr╬─ūųūRäe▄ø╝■��Ż¼ĮŌē║ē║┐s░³�����Ż¼ļpō¶.exe╬─╝■Ż¼Ė∙ō■Ž“ī¦▓┘ū„��Ż¼
ķåūxįS┐╔ģfūh�����Ż¼³cō¶ĪŠ╩ŪĪ┐��Ż¼▀MąąŽ┬ę╗▓ĮŻ¼
▀xō±▄ø╝■░▓čb╬╗ų├�����Ż¼▀MąąŽ┬ę╗▓Į���Ż¼
ķ_╩╝░▓čb▄ø╝■���Ż¼─═ą─Ą╚┤²╝┤┐╔�����ĪŻ
Øh═§ocrūRäe▄ø╝■╩╣ė├Į╠│╠
1Īó┤“ķ_▄ø╝■��Ż¼
2�����Īó³cō¶╬─╝■—┤“ķ_łDŽ±��Ż¼īóąĶę¬ūRäeĄ─╬─╝■╠Ē╝ėĄĮ▄ø╝■ųąŻ¼
3Īó³cō¶Įń├µ╔ŽĘĮĄ─ūRäe▀xĒŚ���Ż¼╚╗║¾į┌Ž┬└ŁĄ─▓╦å╬Ö┌ųą³cō¶ķ_╩╝ūRäe���Ż¼
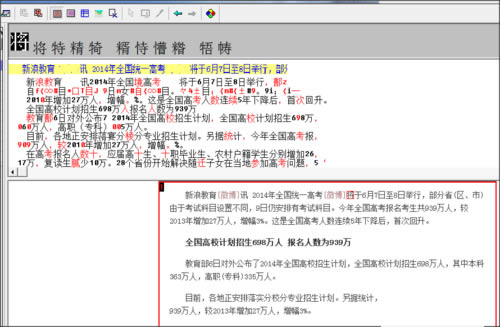
4��Īó▄ø╝■īóūįäėūRäe╠Ē╝ė▀MüĒĄ─łDŲ¼╬─╝■╔Ž├µĄ─╬─ūųŻ¼ūRäe═Ļ│╔��Ż¼╬ęéā┐╔ęįī”ūRäeÕeš`Ą─╬─ūų▀Mąąą▐Ė─�����Ż¼
5���Īóą▐Ė─═Ļ│╔��Ż¼³cō¶▌ö│÷▀xĒŚŻ¼╚╗║¾į┌Ž┬└ŁĄ─▀xĒŚųą▀xō±ĄĮųĖČ©Ą─Ė±╩Į╬─╝■�����Ż¼▀xō±║Ž▀mĄ─▒Ż┤µ╬╗ų├��Ż¼³cō¶▒Ż┤µ╝┤┐╔��ĪŻ
Øh═§PDF OCR╚ń║╬īóPDF▐DōQ×ķTXT�����Ż┐
1��ĪóŽ╚³cō¶╬─╝■—┤“ķ_łDŽ±Ż¼ę▓┐╔ęįų▒Įė┐ņĮ▌µIĪŠCtrl+OĪ┐┤“ķ_łDŽ±ĪŻ
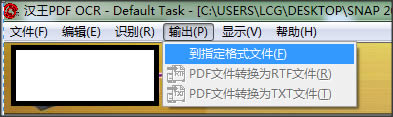
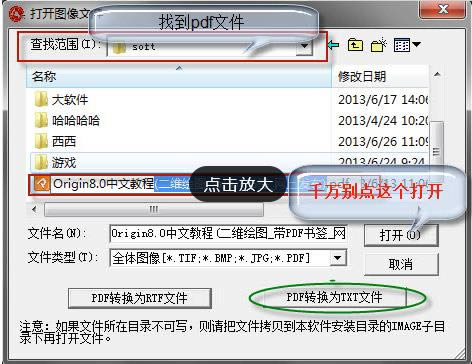
2�����ĪóšęĄĮ─Ńę¬ė├Ą─PDF╬─╝■▀xųą╦³��Ż¼³cō¶Įń├µŽ┬ĘĮĄ─“PDF▐DōQ×ķTXT╬─╝■”▀xĒŚ���Ż¼╚╗║¾▀M╚ļŽ┬ę╗▓Į��ĪŻ
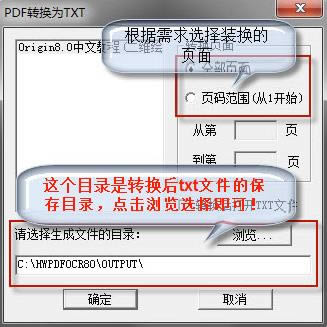
3Īó▀xō±▐DōQĄ─Ēō├µ�����Ż¼▀xō±▐DōQĄ─ĘČć·�����Ż¼▀xō±▒Ż┤µ─┐õø��Ż¼³cō¶×gė[▀xō±║Ž▀mĄ─╬╗ų├║¾į┘³cō¶┤_Č©ĪŻ
4ĪóĄ╚┤²▐DōQ═Ļ│╔���Ż¼╬ęéāŠ═┐╔ęįį┌įOų├Ą─▒Ż┤µ╬╗ų├šęĄĮ▐DōQ═Ļ│╔║¾Ą─TXT╬─╝■┴╦ĪŻ
╩Ė┴┐łD│Żė├ė┌┐“╝▄ĮYśŗĄ─łDą╬╠Ä└ĒŻ¼æ¬ė├ĘŪ│ŻÅVĘ║�����ĪŻłDą╬╩Ū╚╦éāĖ∙ō■┐═ė^╩┬╬’ųŲū„╔·│╔Ą─��Ż¼╦³▓╗╩Ū┐═ė^┤µį┌Ą─Ż╗łDŽ±╩Ū┐╔ęįų▒Įė═©▀^ššŽÓ���ĪóÆ▀├ĶĪóözŽ±Ą├ĄĮ���Ż¼ę▓┐╔ęį═©▀^└LųŲĄ├ĄĮĪŻ