įö╝Üšf├„į┌mysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“┼cā×(y©Łu)╗»ĘĮĘ©
░l(f©Ī)▒ĒĢrķgŻ║2023-07-11 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP▄ø╝■ŽÓĻP╬─š┬╚╦ÜŌŻ║
[š¬ę¬]mysql▓ķįā╩╣ė├select├³┴ŅŻ¼┼õ║ŽlimitŻ¼offsetģóöĄ┐╔ęįūx╚ĪųĖČ©ĘČć·Ą─ėøõøĪŻ▒Š╬─īóĮķĮBmysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“╝░ā×(y©Łu)╗»ĘĮĘ©ĪŻ £╩éõ£yįćöĄō■▒Ē╝░öĄō■1.äō(chu©żng)Į©▒ĒCR...
mysql▓ķįā╩╣ė├select├³┴ŅŻ¼┼õ║ŽlimitŻ¼offsetģóöĄ┐╔ęįūx╚ĪųĖČ©ĘČć·Ą─ėøõøĪŻ▒Š╬─īóĮķĮBmysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“╝░ā×(y©Łu)╗»ĘĮĘ©ĪŻ
£╩éõ£yįćöĄō■▒Ē╝░öĄō■
1.äō(chu©żng)Į©▒Ē
CREATE TABLE `member` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(10) NOT NULL COMMENT 'ąš├¹', `gender` tinyint(3) unsigned NOT NULL COMMENT 'ąįäe', PRIMARY KEY (`id`), KEY `gender` (`gender`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
2.▓Õ╚ļ1000000Ślėøõø
<?php
$pdo = new PDO("mysql:host=localhost;dbname=user","root",'');for($i=0; $i<1000000; $i++){ $name = substr(md5(time().mt_rand(000,999)),0,10); $gender = mt_rand(1,2); $sqlstr = "insert into member(name,gender) values('".$name."','".$gender."')"; $stmt = $pdo->prepare($sqlstr); $stmt->execute();}
?>mysql> select count(*) from member;
+----------+ count(*)
+----------+ 1000000
+----------+1 row in set (0.23 sec)
3.«öŪ░öĄō■Äņ░µ▒Š
mysql> select version();
+-----------+ version()
+-----------+ 5.6.24
+-----------+1 row in set (0.01 sec)
Ęų╬÷offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“
1.offset▌^ąĪĄ─Ūķør
mysql> select * from member where gender=1 limit 10,1;
+----+------------+--------+ id name gender
+----+------------+--------+ 26 509e279687 1
+----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 100,1;
+-----+------------+--------+ id name gender
+-----+------------+--------+ 211 07c4cbca3a 1
+-----+------------+--------+1 row in set (0.00 sec)mysql> select * from member where gender=1 limit 1000,1;
+------+------------+--------+ id name gender
+------+------------+--------+ 1975 e95b8b6ca1 1
+------+------------+--------+1 row in set (0.00 sec)
«öoffset▌^ąĪĢrŻ¼▓ķįā╦┘Č╚║▄┐ņŻ¼ą¦┬╩▌^Ė▀ĪŻ
2.offset▌^┤¾Ą─Ūķør
mysql> select * from member where gender=1 limit 100000,1;
+--------+------------+--------+ id name gender
+--------+------------+--------+ 199798 540db8c5bc 1
+--------+------------+--------+1 row in set (0.12 sec)mysql> select * from member where gender=1 limit 200000,1;
+--------+------------+--------+ id name gender
+--------+------------+--------+ 399649 0b21fec4c6 1
+--------+------------+--------+1 row in set (0.23 sec)mysql> select * from member where gender=1 limit 300000,1;
+--------+------------+--------+ id name gender
+--------+------------+--------+ 599465 f48375bdb8 1
+--------+------------+--------+1 row in set (0.31 sec)
«öoffset║▄┤¾ĢrŻ¼Ģ■│÷¼Fą¦┬╩å¢Ņ}Ż¼ļSų°offsetĄ─į÷┤¾Ż¼ł╠(zh©¬)ąąą¦┬╩Ž┬ĮĄĪŻ
Ęų╬÷ė░Ēæąį─▄įŁę“
select * from member where gender=1 limit 300000,1;
ę“×ķöĄō■▒Ē╩ŪInnoDBŻ¼Ė∙ō■InnoDB╦„ę²Ą─ĮYśŗŻ¼▓ķįā▀^│╠×ķŻ║
═©▀^Č■╝ē╦„ę²▓ķĄĮų„µIųĄŻ©šę│÷╦∙ėągender=1Ą─id)ĪŻ
į┘Ė∙ō■▓ķĄĮĄ─ų„µIųĄ═©▀^ų„µI╦„ę²šęĄĮŽÓæ¬Ą─öĄō■ēKŻ©Ė∙ō■idšę│÷ī”æ¬Ą─öĄō■ēKā╚╚▌Ż®ĪŻ
Ė∙ō■offsetĄ─ųĄŻ¼▓ķįā300001┤╬ų„µI╦„ę²Ą─öĄō■Ż¼ūŅ║¾īóų«Ū░Ą─300000ŚlüGŚēŻ¼╚Ī│÷ūŅ║¾1ŚlĪŻ
▓╗▀^╝╚╚╗Č■╝ē╦„ę²ęčĮøšęĄĮų„µIųĄŻ¼×ķ╩▓├┤▀ĆąĶꬎ╚ė├ų„µI╦„ę²šęĄĮöĄō■ēKŻ¼į┘Ė∙ō■offsetĄ─ųĄū÷Ų½ęŲ╠Ä└Ē─žŻ┐
╚ń╣¹į┌šęĄĮų„µI╦„ę²║¾Ż¼Ž╚ł╠(zh©¬)ąąoffsetŲ½ęŲ╠Ä└ĒŻ¼╠°▀^300000ŚlŻ¼į┘═©▀^Ą┌300001ŚlėøõøĄ─ų„µI╦„ę²╚źūx╚ĪöĄō■ēKŻ¼▀@śėŠ═─▄╠ßĖ▀ą¦┬╩┴╦ĪŻ
╚ń╣¹╬ęéāų╗▓ķįā│÷ų„µIŻ¼┐┤┐┤ėą╩▓├┤▓╗═¼
mysql> select id from member where gender=1 limit 300000,1;
+--------+ id
+--------+ 599465
+--------+1 row in set (0.09 sec)
║▄├„’@Ż¼╚ń╣¹ų╗▓ķįāų„µIŻ¼ł╠(zh©¬)ąąą¦┬╩ī”▒╚▓ķįā╚½▓┐ūųČ╬Ż¼ėą║▄┤¾Ą─╠ß╔²ĪŻ
═Ų£y
ų╗▓ķįāų„µIĄ─Ūķør
ę“×ķČ■╝ē╦„ę²ęčĮøšęĄĮų„µIųĄŻ¼Č°▓ķįāų╗ąĶę¬ūx╚Īų„µIŻ¼ę“┤╦mysqlĢ■Ž╚ł╠(zh©¬)ąąoffsetŲ½ęŲ▓┘ū„Ż¼į┘Ė∙ō■║¾├µĄ─ų„µI╦„ę²ūx╚ĪöĄō■ēKĪŻ
ąĶę¬▓ķįā╦∙ėąūųČ╬Ą─Ūķør
ę“×ķČ■╝ē╦„ę²ų╗šęĄĮų„µIųĄŻ¼Ą½Ųõ╦¹ūųČ╬Ą─ųĄąĶę¬ūx╚ĪöĄō■ēK▓┼─▄½@╚ĪĪŻę“┤╦mysqlĢ■Ž╚ūx│÷öĄō■ēKā╚╚▌Ż¼į┘ł╠(zh©¬)ąąoffsetŲ½ęŲ▓┘ū„Ż¼ūŅ║¾üGŚēŪ░├µąĶę¬╠°▀^Ą─öĄō■Ż¼ĘĄ╗ž║¾├µĄ─öĄō■ĪŻ
ūCīŹ
InnoDBųąėąbuffer poolŻ¼┤µĘ┼ūŅĮ³įLå¢▀^Ą─öĄō■ĒōŻ¼░³└©öĄō■Ēō║═╦„ę²ĒōĪŻ
×ķ┴╦£yįćŻ¼Ž╚░čmysqlųžåóŻ¼ųžåó║¾▓ķ┐┤buffer poolĄ─ā╚╚▌ĪŻ
mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
Empty set (0.04 sec)┐╔ęį┐┤ĄĮŻ¼ųžåó║¾Ż¼ø]ėąįLå¢▀^╚╬║╬Ą─öĄō■ĒōĪŻ
▓ķįā╦∙ėąūųČ╬Ż¼į┘▓ķ┐┤buffer poolĄ─ā╚╚▌
mysql> select * from member where gender=1 limit 300000,1;
+--------+------------+--------+ id name gender
+--------+------------+--------+ 599465 f48375bdb8 1
+--------+------------+--------+1 row in set (0.38 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+ index_name count(*)
+------------+----------+ gender 261 PRIMARY 1385
+------------+----------+2 rows in set (0.06 sec)┐╔ęį┐┤│÷Ż¼┤╦Ģrbuffer poolųąĻPė┌member▒Ēėą1385éĆöĄō■ĒōŻ¼261éĆ╦„ę²ĒōĪŻ
ųžåómysqlŪÕ┐šbuffer poolŻ¼└^└m(x©┤)£yįćų╗▓ķįāų„µI
mysql> select id from member where gender=1 limit 300000,1;
+--------+ id
+--------+ 599465
+--------+1 row in set (0.08 sec)mysql> select index_name,count(*) from information_schema.INNODB_BUFFER_PAGE where INDEX_NAME in('primary','gender') and TABLE_NAME like '%member%' group by index_name;
+------------+----------+ index_name count(*)
+------------+----------+ gender 263 PRIMARY 13
+------------+----------+2 rows in set (0.04 sec)┐╔ęį┐┤│÷Ż¼┤╦Ģrbuffer poolųąĻPė┌member▒Ēų╗ėą13éĆöĄō■ĒōŻ¼263éĆ╦„ę²ĒōĪŻę“┤╦£p╔┘┴╦ČÓ┤╬═©▀^ų„µI╦„ę²įLå¢öĄō■ēKĄ─I/O▓┘ū„Ż¼╠ßĖ▀ł╠(zh©¬)ąąą¦┬╩ĪŻ
ę“┤╦┐╔ęįūCīŹŻ¼mysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“╩ŪČÓ┤╬═©▀^ų„µI╦„ę²įLå¢öĄō■ēKĄ─I/O▓┘ū„ĪŻŻ©ūóęŌŻ¼ų╗ėąInnoDBėą▀@éĆå¢Ņ}Ż¼Č°MYISAM╦„ę²ĮYśŗ┼cInnoDB▓╗═¼Ż¼Č■╝ē╦„ę²Č╝╩Ūų▒ĮėųĖŽ“öĄō■ēKĄ─Ż¼ę“┤╦ø]ėą┤╦å¢Ņ} Ż®ĪŻ
InnoDB┼cMyISAMę²Ūµ╦„ę²ĮYśŗī”▒╚łD
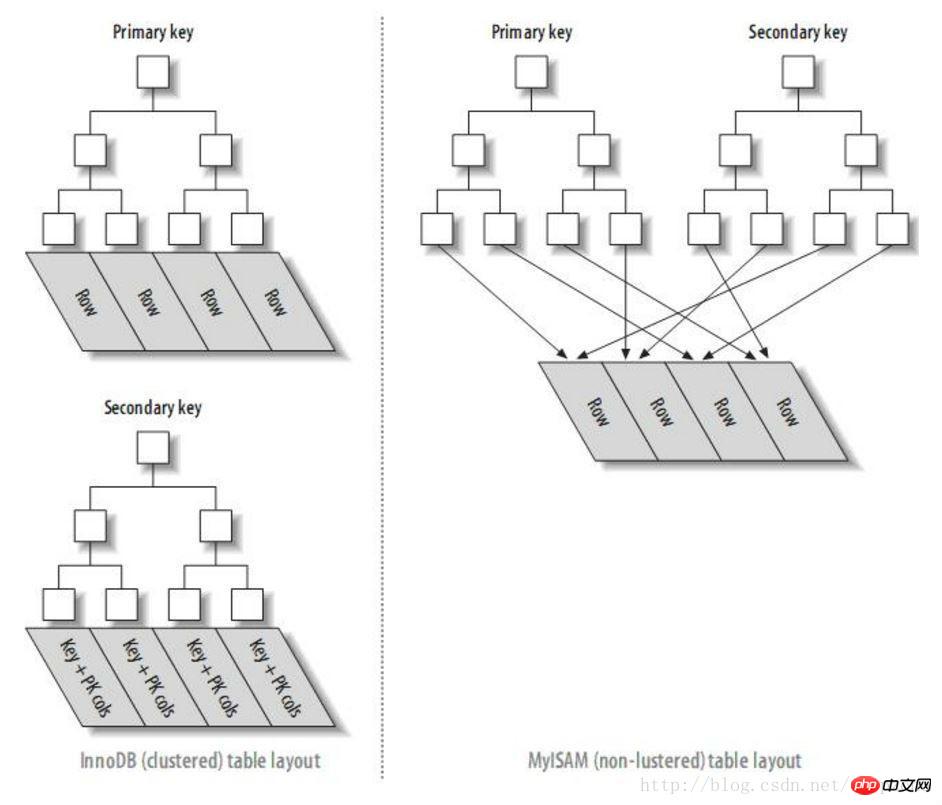
ā×(y©Łu)╗»ĘĮĘ©
Ė∙ō■╔Ž├µĄ─Ęų╬÷Ż¼╬ęéāų¬Ą└▓ķįā╦∙ėąūųČ╬Ģ■ī¦ų┬ų„µI╦„ę²ČÓ┤╬įLå¢öĄō■ēKįņ│╔Ą─I/O▓┘ū„ĪŻ
ę“┤╦╬ęéāŽ╚▓ķ│÷Ų½ęŲ║¾Ą─ų„µIŻ¼į┘Ė∙ō■ų„µI╦„ę²▓ķįāöĄō■ēKĄ─╦∙ėąā╚╚▌╝┤┐╔ā×(y©Łu)╗»ĪŻ
mysql> select a.* from member as a inner join (select id from member where gender=1 limit 300000,1) as b on a.id=b.id;
+--------+------------+--------+ id name gender
+--------+------------+--------+ 599465 f48375bdb8 1
+--------+------------+--------+1 row in set (0.08 sec)
▒ŠŲ¬╬─š┬ųvĮŌ┴╦į┌mysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“┼cā×(y©Łu)╗»ĘĮĘ© Ż¼Ė³ČÓŽÓĻPā╚╚▌šłĻPūóphpųą╬─ŠWĪŻ
ŽÓĻP═Ų╦]Ż║
ĻPė┌php╩╣ė├š²ät╚ź│²īÆĖ▀śė╩ĮĄ─ĘĮĘ©
įöĮŌ╬─╝■ā╚╚▌╚źųž╝░┼┼ą“ Ą─ŽÓĻPā╚╚▌
ĮŌūxmysql┤¾ąĪīæ├¶Ėą┼õų├å¢Ņ}
ęį╔ŽŠ═╩ŪįöĮŌį┌mysql▓ķįāĢrŻ¼offset▀^┤¾ė░Ēæąį─▄Ą─įŁę“┼cā×(y©Łu)╗»ĘĮĘ©Ą─įö╝Üā╚╚▌Ż¼Ė³ČÓšłĻPūóphpųą╬─ŠWŲõ╦³ŽÓĻP╬─š┬ŻĪ
īW┴ĢĮ╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
