▒O(ji©Īn)┐žMySQLĄ─ę╗Ų╩š╝»▒Ēą┼Žó┤·┤aįö╝Ü(x©¼)šf├„Ż©łD╬─Ż®
░l(f©Ī)▒ĒĢrķgŻ║2023-09-10 üĒį┤Ż║├„▌xšŠš¹└ĒŽÓĻP(gu©Īn)▄ø╝■ŽÓĻP(gu©Īn)╬─š┬╚╦ÜŌŻ║
[š¬ę¬]1. Storyę▓įS─ŃĮø(j©®ng)│ŻĢ■▒╗å¢ĄĮŻ¼Äņ└’─│éĆ▒ĒūŅĮ³ę╗─ĻĄ─ā╚(n©©i)├┐éĆį┬Ą─öĄ(sh©┤)ō■(j©┤)┴┐į÷ķLŪķørĪŻ«ö(d©Īng)╚╗╚ń╣¹─Ńėą░┤į┬Ęų▒Ē▒╚▌^║├▐kŻ¼░żéĆ show table statusŻ¼╚ń╣¹ų╗ėąę╗éĆ┤¾▒ĒŻ¼─Ū╣└ėŗę¬į┌┤¾╝ęČ╝ą▌ŽóĄ─Ģr║“Ż¼╝┼─»Ą─ę╣└’╚ź┼▄sqlĮy(t©»ng)ėŗ┴╦Ż¼ę“×ķ─Ńų╗─▄½@╚Ī«ö(d©Īng)Ū░Ą─▒Ēą┼ŽóŻ¼Üv╩Ęą┼ŽóūĘ▓ķ▓╗ĄĮ┴╦ĪŻ│²┤╦ęį═ŌŻ¼ū„×ķDBA▒Š...
1. Story
ę▓įS─ŃĮø(j©®ng)│ŻĢ■▒╗å¢ĄĮŻ¼Äņ└’─│éĆ▒ĒūŅĮ³ę╗─ĻĄ─ā╚(n©©i)├┐éĆį┬Ą─öĄ(sh©┤)ō■(j©┤)┴┐į÷ķLŪķørĪŻ«ö(d©Īng)╚╗╚ń╣¹─Ńėą░┤į┬Ęų▒Ē▒╚▌^║├▐kŻ¼░żéĆ show table statusŻ¼╚ń╣¹ų╗ėąę╗éĆ┤¾▒ĒŻ¼─Ū╣└ėŗę¬į┌┤¾╝ęČ╝ą▌ŽóĄ─Ģr║“Ż¼╝┼─»Ą─ę╣└’╚ź┼▄sqlĮy(t©»ng)ėŗ┴╦Ż¼ę“×ķ─Ńų╗─▄½@╚Ī«ö(d©Īng)Ū░Ą─▒Ēą┼ŽóŻ¼Üv╩Ęą┼ŽóūĘ▓ķ▓╗ĄĮ┴╦ĪŻ
│²┤╦ęį═ŌŻ¼ū„×ķDBA▒Š╔Ēę▓ę¬ī”öĄ(sh©┤)ō■(j©┤)Äņ┐šķgį÷ķLŪķør▀MąąŅA(y©┤)╣└Ż¼ė├ęįęÄ(gu©®)äØ╚▌┴┐ĪŻ╬ęéāšfĄ─▒Ēą┼Žóų„ę¬░³└©Ż║
▒ĒöĄ(sh©┤)ō■(j©┤)┤¾ąĪŻ©DATA_LENGTHŻ®
╦„ę²┤¾ąĪ(INDEX_LENGTH)
ąąöĄ(sh©┤)Ż©ROWSŻ®
«ö(d©Īng)Ū░ūįį÷ųĄŻ©AUTO_INCREMENTŻ¼╚ń╣¹ėąŻ®
─┐Ū░╩Ūø]ėą┐┤ĄĮ──éĆmysql▒O(ji©Īn)┐ž╣żŠ▀╔Ž╠ß╣®▀@śėĄ─ųĖś╦(bi©Īo)ĪŻ▀@ą®ą┼Žó▓╗ąĶę¬▓╔╝»Ą─╠½ŅlĘ▒Ż¼Č°ŪęĮY(ji©”)╣¹ę▓ų╗╩ŪéĆŅA(y©┤)╣└ųĄŻ¼▓╗ę╗Č©£╩(zh©│n)┤_Ż¼╦∙ęį▀@╩ŪšŠį┌ę╗éĆ╚½ŠųĪóķL▀h(yu©Żn)Ą─ĮŪČ╚╚ź▒O(ji©Īn)┐ž(▓╔╝»)▒ĒĄ─ĪŻ
▒Š╬─ę¬ĮķĮBĄ─ūį╝║īæĄ─▓╔╝»╣żŠ▀Ż¼╩Ū╗∙ė┌ĮMā╚(n©©i)¼F(xi©żn)ėąĄ─ę╗╠ū▒O(ji©Īn)┐ž¾wŽĄŻ║
InfluxDBŻ║Ģrķgą“┴ąöĄ(sh©┤)ō■(j©┤)ÄņŻ¼┤µā”▒O(ji©Īn)┐žöĄ(sh©┤)ō■(j©┤)
GrafanaŻ║öĄ(sh©┤)ō■(j©┤)š╣╩Š├µ░Õ
TelegrafŻ║╩š╝»ą┼ŽóĄ─agent
┐┤┴╦Ž┬ telegraf Ą─ūŅą┬Ą─ mysql ▓Õ╝■Ż¼ę╗ķ_╩╝║▄ą└╬┐Ż║ų¦│ų╩š╝» Table schema statistics ║═ Info schema auto increment columnsĪŻįćė├┴╦ę╗Ž┬Ż¼ėąöĄ(sh©┤)ō■(j©┤)Ż¼Ą½╩Ū╚ńŪ░├µ╦∙šfŻ¼│²┴╦ūįį÷ųĄ═ŌŲõ╦¹Č╝╩ŪŅA(y©┤)╣└ųĄŻ¼telegraf╩š╝»Ņl┬╩▀^Ė▀ø]╔ČęŌ┴xŻ¼ę▓įSę╗╠ņ2┤╬Š═ūŃē“┴╦Ż¼╦³╠ß╣®Ą─ IntervalSlow▀xĒŚ╣╠Č©īæ╦└į┌┤·┤a└’Ż¼ų╗─▄╩ŪĘ┼ŠÅ global status ▒O(ji©Īn)┐žŅl┬╩ĪŻ▓╗▀^Ą╣╩Ū┐╔ęį┼cŲõ╦³▒O(ji©Īn)┐žųĖś╦(bi©Īo)Ęųķ_│╔ā╔Ę▌┼õų├╬─╝■Ż¼Ė„ūįČ©┴x╩š╝»ķgĖ¶üĒīŹ¼F(xi©żn)ĪŻ
ūŅ║¾┤“╦Ńūį╝║ė├pythonö]ę╗éĆŻ¼╔Žł¾ĄĮinfluxdb└’ :)
2. Concept
═Ļš¹┤·┤aęŖ GitHubĒŚ─┐ĄžųĘŻ║DBschema_gather
īŹ¼F(xi©żn)ę▓╠žäe║åå╬Ż¼Š═╩Ū▓ķįā information_schema ÄņĄ─ COLUMNSĪóTABLES ā╔éĆ▒ĒŻ║
<!-- more -->
SELECT
IFNULL(@@hostname, @@server_id) SERVER_NAME,
%s as HOST,
t.TABLE_SCHEMA,
t.TABLE_NAME,
t.TABLE_ROWS,
t.DATA_LENGTH,
t.INDEX_LENGTH,
t.AUTO_INCREMENT,
c.COLUMN_NAME,
c.DATA_TYPE,
LOCATE('unsigned', c.COLUMN_TYPE) COL_UNSIGNED
# CONCAT(c.DATA_TYPE, IF(LOCATE('unsigned', c.COLUMN_TYPE)=0, '', '_unsigned'))
FROM
information_schema.`TABLES` t
LEFT JOIN information_schema.`COLUMNS` c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
AND c.EXTRA = 'auto_increment'
WHERE
t.TABLE_SCHEMA NOT IN (
'mysql',
'information_schema',
'performance_schema',
'sys'
)
AND t.TABLE_TYPE = 'BASE TABLE'ĻP(gu©Īn)ė┌ auto_incrementŻ¼╬ęéā│²┴╦ĻP(gu©Īn)ūó«ö(d©Īng)Ū░į÷ķLĄĮ──┴╦Ż¼▀ĆĢ■į┌ęŌŽÓ▒╚ int / bigint Ą─ūŅ┤¾ųĄŻ¼▀ĆėąČÓ╔┘┐╔ė├┐šķgĪŻė┌╩Ūėŗ╦Ń┴╦ autoIncrUsage ▀@ę╗┴ąŻ¼ė├ė┌▒Ż┤µ«ö(d©Īng)Ū░ęč╩╣ė├Ą─▒╚└²ĪŻ
╚╗║¾╩╣ė├ InfluxDB Ą─python┐═æ¶Č╦Ż¼┼·┴┐┤µ╚ļinfluxdbĪŻ╚ń╣¹ø]ėąInfluxDBŻ¼ĮY(ji©”)╣¹Ģ■┤“ėĪ│÷json Ī¬Ī¬ ▀@╩ŪZabbixĪóOpen-Falcon▀@ą®▒O(ji©Īn)┐ž╣żŠ▀Ųš▒ķų¦│ųĄ─Ė±╩ĮĪŻ
ūŅ║¾Š═╩Ū╩╣ė├ Grafana Å─ influxdb öĄ(sh©┤)ō■(j©┤)į┤«ŗłDĪŻ
3. Usage
Łh(hu©ón)Š│
į┌ python 2.7 Łh(hu©ón)Š│Ž┬ŠÄīæĄ─Ż¼2.6Ż¼3.xø]£yĪŻ
▀\ąąąĶę¬MySQLdbĪóinfluxdbā╔éĆÄņŻ║
$ sudo pip install mysql-python influxdb
┼õų├
settings_dbs.py ┼õų├╬─╝■
InfluxDB_INFOŻ║influxdbĄ─▀BĮėą┼ŽóŻ¼ūóęŌ╠ßŪ░äō(chu©żng)Į©║├öĄ(sh©┤)ō■(j©┤)Äņ├¹ mysql_info
įO(sh©©)ų├×ķ None ┐╔▌ö│÷ĮY(ji©”)╣¹×ķjson.
äō(chu©żng)Į©influxdb╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Äņ║═┤µā”▓▀┬į
┤µĘ┼2─ĻŻ¼1éĆÅ═(f©┤)ųŲ╝»Ż║Ż©░┤ąĶš{(di©żo)š¹Ż®
CREATE DATABASE "mysql_info"
CREATE RETENTION POLICY "mysql_info_schema" ON "mysql_info" DURATION 730d REPLICATION 1 DEFAULT
┐┤┤¾Ą─ą┼ŽóŅÉ╦Ųė┌Ż║
Ę┼crontab┼▄
┐╔ęįå╬¬ÜĘ┼į┌ė├ė┌▒O(ji©Īn)┐žĄ─Ę■äš(w©┤)Ų„╔ŽŻ¼▓╗▀^Į©ūhį┌╔·«a(ch©Żn)Łh(hu©ón)Š│┐╔ęį▀\ąąį┌mysqlīŹ└²╦∙į┌ų„ÖC╔ŽŻ¼░▓╚½ŲęŖĪŻ
ę╗░ŃÄņį┌═Ē╔ŽĢ■ėąöĄ(sh©┤)ō■(j©┤)▀węŲĄ─äėū„Ż¼┐╔ęįį┌▀węŲŪ░║¾Ęųäe▀\ąą mysql_schema_info.py üĒ╩š╝»ę╗┤╬ĪŻ▓╗Į©ūh╠½ŅlĘ▒ĪŻ
40 23,5,12,18 * * * /opt/DBschema_info/mysql_schema_info.py >> /tmp/collect_DBschema_info.log 2>&1
╔·│╔łD▒Ē
ī¦(d©Żo)╚ļĒŚ─┐Ž┬Ą─ grafana_table_stats.json ĄĮ Grafana├µ░ÕųąĪŻą¦╣¹╚ńŽ┬Ż║

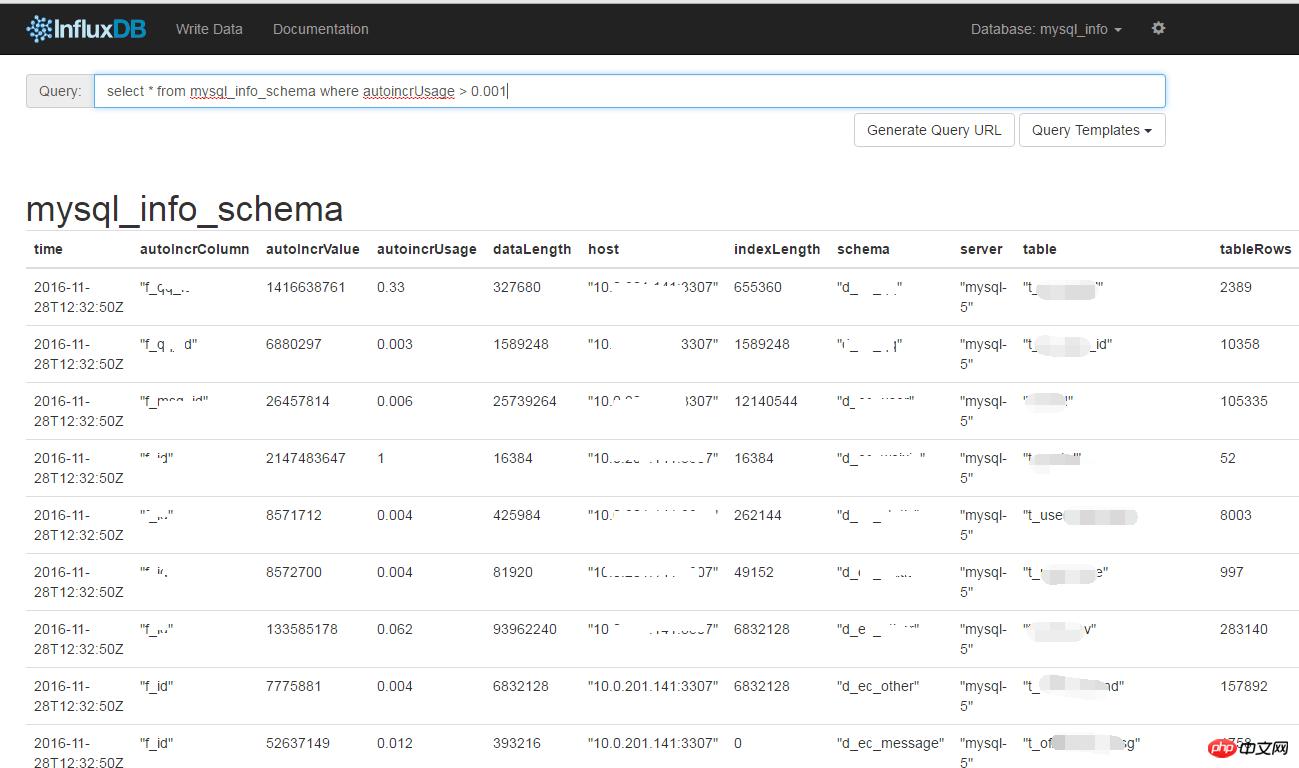
▒ĒöĄ(sh©┤)ō■(j©┤)┤¾ąĪ║═ąąöĄ(sh©┤)
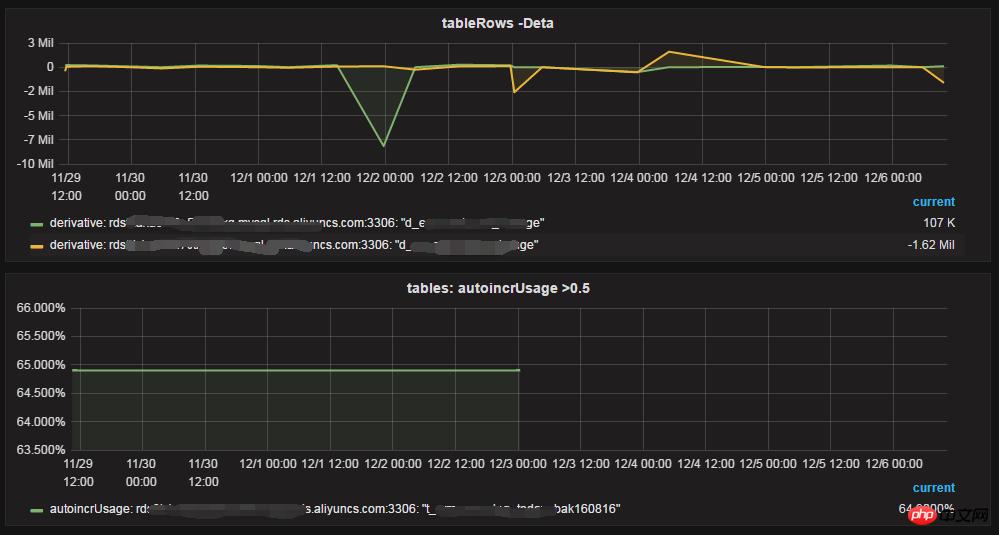
├┐╠ņąąöĄ(sh©┤)ūā╗»į÷┴┐,auto_increment╩╣ė├┬╩
4. More
ĘųÄņĘų▒ĒŪķørŽ┬Ż¼╚½Šų╬©ę╗IDį┌▒Ē└’¤oĘ©ėŗ╦Ń autoIncrUsage
īŹ¼F(xi©żn)╔ŽŲõīŹ║▄║åå╬Ż¼Ė³ų„ꬥ─╩ŪåŠąč╩š╝»▀@ą®ą┼ŽóĄ─ęŌūR
┐╔ęįį÷╝ė Graphite ▌ö│÷Ė±╩Į
ęį╔ŽŠ═╩Ū▒O(ji©Īn)┐žMySQLĄ─═¼Ģr╩š╝»▒Ēą┼Žó┤·┤aįöĮŌŻ©łD╬─Ż®Ą─įö╝Ü(x©¼)ā╚(n©©i)╚▌Ż¼Ė³ČÓšłĻP(gu©Īn)ūóphpųą╬─ŠW(w©Żng)Ųõ╦³ŽÓĻP(gu©Īn)╬─š┬ŻĪ
īW(xu©”)┴Ģ(x©¬)Į╠│╠┐ņ╦┘šŲ╬šÅ─╚ļķTĄĮŠ½═©Ą─SQLų¬ūRĪŻ
